
感知哈希(Perceptual Hash, PHash)是用来做图像拷贝检索(Copy Detection)最容易操作的一种方法,实际上除了感知哈希、均值哈希,还有很多的从图像本身出发计算出来的图像哈希值,在OpenCV 3.3及其以后的版本中,包含了很多图像哈希的计算方法,具体的可以参考The module brings implementations of different image hashing algorithms,其中各种图像哈希方法对8种不同变化的抗干扰程度,文档中做了一个很好的总结:

从图中可以看到,Phash具备较好的对不同变化的抗干扰性,因为在一般要求不高的图像拷贝检索场景中,应用得较多。下面小白菜就PHash的原理(计算步骤)、在使用中存在的问题以及改进方案做一个记录与总结。
PHash原理
感知哈希比均值哈希要稳健,PHash使用DCT将图像由空域转为频域,并对频域的低频成分进行散列化。PHash算法可分为以下几个步骤:
- 将图片resize到32*32最好,这样可以简化DCT计算;
- 将彩色图像转为灰度图像;
- 计算DCT,使用32*32的DCT变换;
- DCT的结果是32*32的矩阵,只要保留左上角的8*8矩阵就可以了,因为这部分呈现了图片中的最低频率;
- 计算DCT的平均值;
- 根据8*8的DCT矩阵来与平均值进行比较,大于平均值的为1,小于的为0。
注意:在保留左上角的8*8矩阵的时候,不一定非得是最左上角,可以往右下移一个或几个像素。下面是采用PHash做拷贝检索结果:
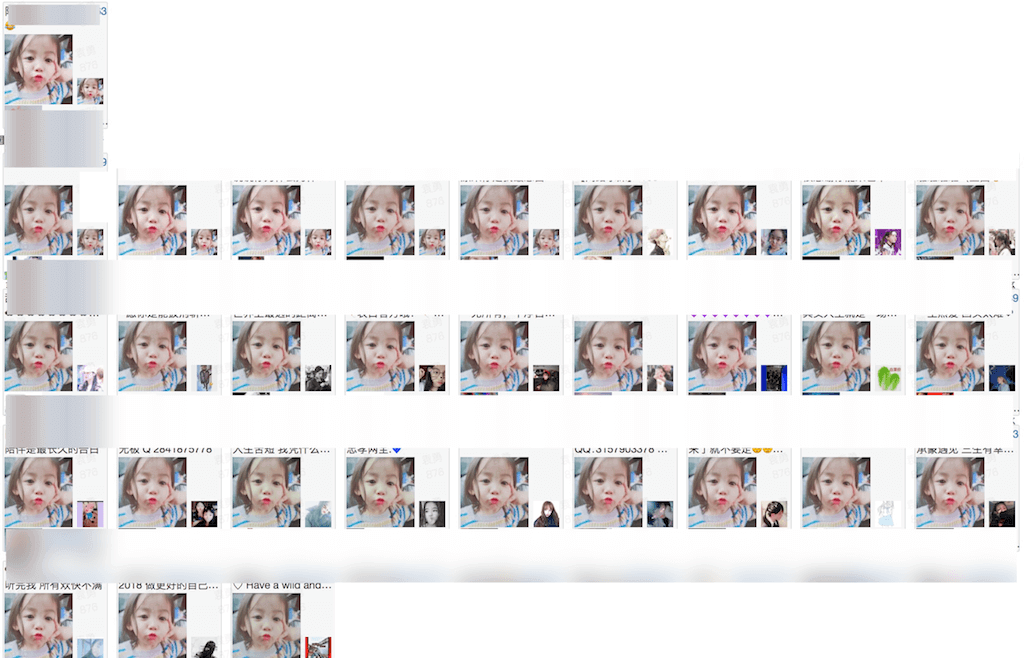
可以看到,对于上面查询,PHash能够获得很好的拷贝检索准确率,但是PHash除了上面图表所示的对椒盐噪声、旋转几乎不具有抗干扰特性外,还有一些其他方面的局限,具体在PHash特征里进行了总结。
PHash特性
PHash对噪声、模糊、jpeg压缩等具备较好的不变性,当然,除了优点外,还应当清楚其局限性。
PHash局限
PHash为了容忍图像的一些形变而只取了图像的低频部分,从而造成了特征捕获不到图像的细节部分,使得对于纯色或者近似纯色图像在做查重的时候并不是很理想。具体地说,由于PHash取的是dct的左上角部分,属于低频成分,也就是关注的是图像的大致外形,没有关注细节,所以对于纯色图片或者近似纯色图片,就没法捕获到它的轮廓细节,导致对纯色图像或者近似纯色图片的查重准确率不高。一种改进的方式是:把这个取的部分往右下移,这样就可以获得图像的轮廓细节,纯色图像或者近似纯色图片查重准确率就会提升,坏处就是轮廓细节取多了,容忍细节变化就小了,导致图像容忍的形变变小,但是这种思路是值得借鉴的。
水平镜像
PHash对镜像不具备不变性,即对图像做水平镜像操作后,不具备不变性能力。可以通过一个简单的实验予以验证。实验过程:测试了两对图片,每一对图片包含图片自身,已经其对应的镜像图片(图片对的大小是一样的,说明为jpeg压缩影响),分别计算图片对之间的距离,一对算出来的距离是35,一对算出来的是33。说明PHash对镜像无召回能力。
既然谈到了图像的镜像变换,我们不妨对PHash、基于SIFT特征的Fisher Vector以及DL相似特征对镜像变换是否有不变形做一个整理:
| 特征 | 形变 | 是否抗干扰 | 备注 |
|---|---|---|---|
| PHash特征 | 镜像 | 否 | 见上面说的验证过程 |
| FV特征 | 镜像 | 很弱 | SIFT对镜像不具备不变性,故FV对镜像召回能力很弱,具体参考论文Flip-Invariant SIFT for Copy and Object Detection |
| DL相似特征 | 镜像 | 是 | 由于DL相似特征在训练的时候,数据增强里面包含镜像,DL相似特征对镜像具备旋转特性,检索显示的top@K里面,可以找回镜像的视频,见结果镜像检索结果 |
PHash改进方案
在前面已经提到了PHash对于纯色或近似纯色图像做拷贝检索存在的缺陷,当DCT进行散列化时如果选取的DCT的频率过低,则对纯色或近似纯色图像的拷贝检索存在badcase,如下图所示:
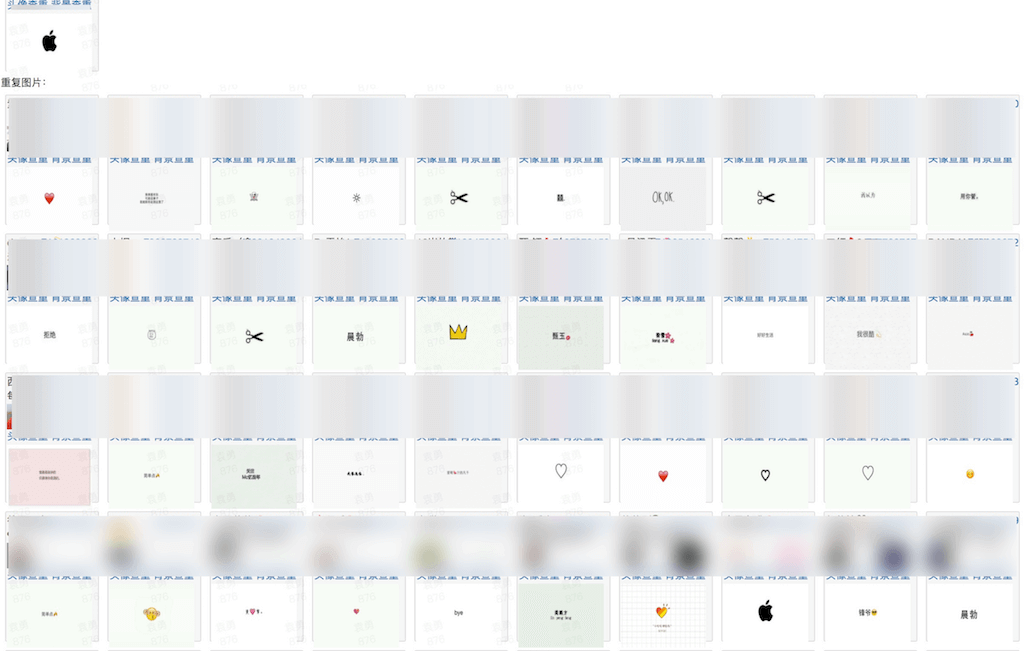
从上图可以看到,由于查询图像是接近纯色的图片,导致取得DCT的低频只能捕获到图像的大致外观,因而很多接近纯色的图片到排在了前面。对这类case的改进优化,我们知道无论是取低频还是高频部分做散列化都不合适,如果只取高频,则会影响正常图片的召回。因此,比较容易想到的一种改进方式是:
- 对于正常的图片,只需采用低频DCT哈希值做排序;
- 对于纯色或近似纯色图像,先用低频DCT哈希值检索排序,然后再用高频DCT哈希值检索再做重排;
这种改进方式的好处是显而易见的,对于每一张图片,只需要额外增加64个比特位的存储空间,并且不用对整个拷贝检索的架构做很大的调整,我们所要做的就是再计算一下高频DCT的哈希值,并且增加一个对纯色或接近纯色的检索服务,就能使PHash在图像拷贝检索上获得较大的精度提升,同时又不至于较大的减少召回。
DCT哈希值,可以采用下面方式进行计算:
// Function: compute image PHash
// Note: to compute normal pHash, set cons = 0; to compute HighFreq pHash, set cons = 15.
// You can adjust the cons to get a better result.
static inline int pHash(const cv::Mat& im, uint64 &hash, int cons) {
if (im.empty()) {
return 0;
}
cv::Mat dct;
imgDct(im, dct);
double dIdex[64];
double mean = 0.0;
uint64_t hashValue = 0;
uint32_t flag = 0;
int k = 0;
for (int i = 1+cons; i < 9+cons; ++i) {
for (int j = 1+cons; j < 9+cons; ++j) {
dIdex[k++] = dct.at<double>(i, j);
mean += dct.at<double>(i, j);
}
}
mean /= 64;
for (int i = 0; i < 32; ++i) {
if (dIdex[i] > mean) {
flag = 1;
flag <<= 31-i;
hashValue |= flag;
}
}
hashValue <<= 32;
for (int i = 32; i < 64; ++i) {
if (dIdex[i] > mean) {
flag = 1;
flag <<= 63 - i;
hashValue |= flag;
}
}
hash = hashValue;
return 1;
}
正常的PHash计算,cons设置为0即可,如果要计算高频PHash,cons推荐设置为15是一个比较好的参数。更完整的实现,请阅读pHash.hpp。
对于图像纯色或接近纯色的检索,小白菜以为应该做得轻巧简洁,因为本身PHash做拷贝检索就是一个很轻量的服务,如果图像纯色或接近纯色的检索做的过重,比如用DL对图像纯色与非纯色进行分类,就失去了用PHash做拷贝检索的意义,另外采用还需消耗大量的GPU,因而图像纯色或接近纯色的服务越轻巧越好。下面小白菜提供的一个极轻量的图像纯色或接近纯色的检测方法:
cv::Mat imGray = cv::imread("123.jpg", CV_LOAD_IMAGE_GRAYSCALE);
int histSize = 256;
float range[] = {0, 255} ;
const float* histRange = {range};
cv::Mat hist;
cv::calcHist(&imGray, 1, 0, cv::Mat(), hist, 1, &histSize, &histRange);
cv::Mat idx;
cv::sortIdx(hist, idx, CV_SORT_EVERY_COLUMN + CV_SORT_DESCENDING);
cv::sort(hist, hist, CV_SORT_EVERY_COLUMN + CV_SORT_DESCENDING);
float maxFre = hist.at<float>(0,0);
float secFre = hist.at<float>(0,1);
float allFre = cv::sum(hist)[0];
float ratio1 = (maxFre + secFre)/allFre;
if(ratio1 >= 0.51){
cout << "pure image" << endl;
}
根据灰度测试的结果,在阈值为0.51时,粗略评估对于纯色或接近纯色图像的召回率至少在85%以上,准确率在90%以上,检测速度在10ms左右。这里,对于召回率和准确率的要求是,召回越高越好,对准确率的要求可以相对低一点,因为我们的目的是要改善纯色或接近纯色图像的拷贝检索的准确率,可以小幅牺牲点非纯色图像拷贝检索的召回。
改善性能验证
按上述所提的改进方案重排后,即:
- 对于一个查询,先使用低频分量DCT哈希值进行排序;
- 对查询图像进行纯色或者近似纯色图像检测,如果不是纯色或者近似纯色图像,当前排序结果为最终拷贝检索排序结果;
- 如果是纯色或者近似纯色图像,使用高频DCT哈希值对初排结果进行重新排序,对重排序结果只保留汉明距离只小于等于某一阈值的那些结果,将其作为最终排序结果;
下面是上面查询图像采用该改进方案重排后的一个结果,如下图所示:

从上面可以看到,经过重排后,对于纯色或者接近纯色图像的拷贝检索,结果有了很大的提升,实际中测试了很多的case,发现都能够获得很好的改善。
总结
在本篇文章中,小白菜就PHash的原理、存在的缺陷以及改进的方案做了详细的总结,这个问题的存在以及想到的解决方法并不是凭空产生和获得的,而是实际应用中确确实实会存在这样或那样的问题,需要不断从原理上推敲,然后反复进行实验。当然对PHash的改进应该有非常多,这种改进方案不一定是最好的,但是可以值得借鉴,希望对有需要的同学有所帮助或者启发。





{kind=link}