
前一段时间山世光老师开源了SeetaFaceEngine,而在小白菜读研的时候,除了做图像检索主要的工作外,也看了一些人脸识别方面的文章,并有过相应的一些笔记Deep Face Recognition论文阅读,所以这次自然也吸引了小白菜测试的兴趣。作为最早一批测试的用户,当时并没有相关资料说明如何在Mac下让它work起来,所以,为了能让它在Xcode中运行,小白菜在SeetaFaceEngine的基础上,对它做了一些小的改动,使得它能够在Xcode里运行起来。当然,在Xcode里面做完了测试后,小白菜在此基础上继续推荐了一步,为它创建了一个QT项目,想在此基础上为它做一个简单的人脸识别和人脸检索的小应用。
人脸识别和人脸检索应用代码:SeetaFaceLib,目前代码还在不断迭代中,已经完成的部分是人脸检索。整个小应用的界面是下面这个样子:
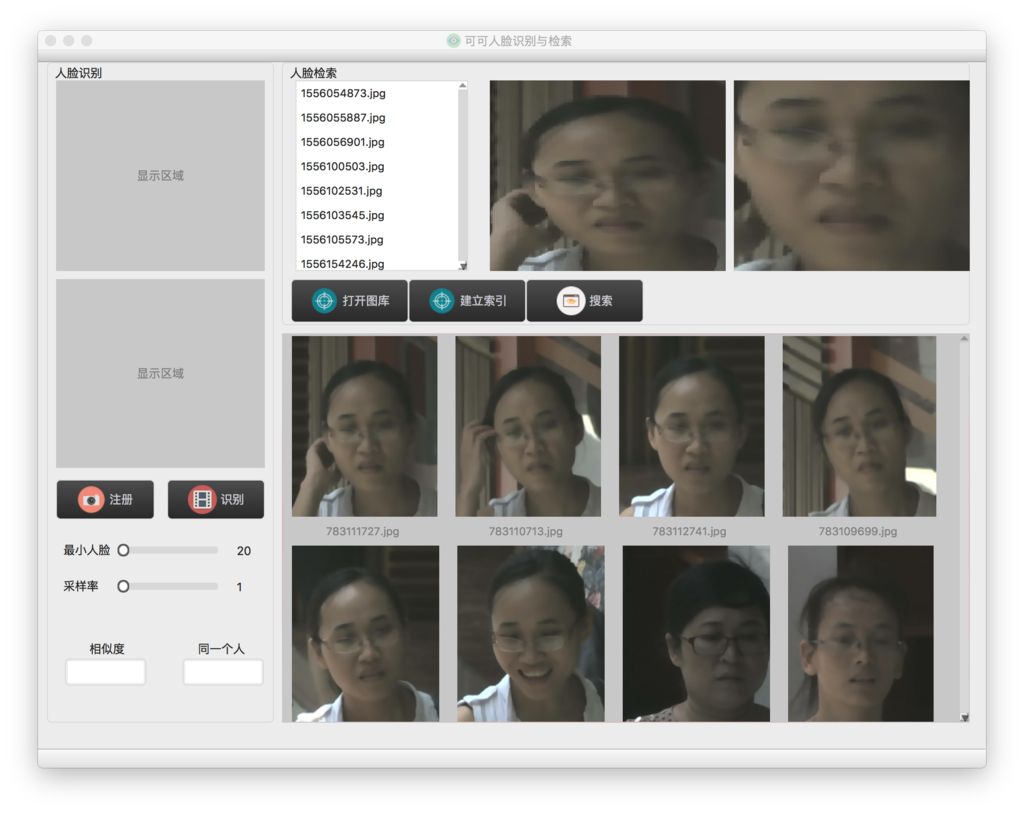
在QT项目刚上传到github上传不久后,远在锐捷的罗兄说这个QT工程对他帮助很大,这个反馈让小白菜深感欣慰。所谓开源,有人用或对人有帮助,这个代码写得就有它的价值了。
回到本篇博客的主题,即我们如何为大规模的描述子建立高效的索引,使得在进行查询的时候,检索系统能够快速地对我们的查询做出响应。对这个问题的探讨,小白菜在之前的文章图像检索:基于内容的图像检索技术以及哈希的文章中做过一些探讨与总结,而人脸检索作为图像检索大范畴的一类具体应用,除了在特征表达上有其自身的特点外,其他过程基本一样。所以在人脸检索中,我们也会碰到图像检索中的3座大山,即:
- 图像数据量大
- 特征维度高
- 要求响应速度快
前两座大山具有相互关联性,涉及到的主题是特征表达的问题,而后一个表象涉及到的是信息检索领域的索引问题。任何有关图像检索方面的问题,几乎都是围绕着这两个核心问题而展开的。对于在这两个方面而展开的工作,暂且不表。我们还是回到人脸检索这个具体的应用中,来谈谈深度描述子的索引问题。
刚开始在建立这个人脸检索QT工程的时候,小白菜并没有做很多复杂的考虑,比如要考虑人脸图像规模,当时建立这个QT工程之初的动机非常简单,就是OpenCV对于检索结果的展示实在是太不方便了,而且小白菜也不需要很大规模的图像体量,另外最重要的一点是,小白菜急切地想看到检索可视化的结果,所以直接用brute-force search的方式应该还ok。但是在做完后,小白菜发现在搜索阶段,搜索不够实时,在小白菜的本机上,3000张的人脸图片,在查询的时候,会出现卡顿的情况,具体表现可以见下图:
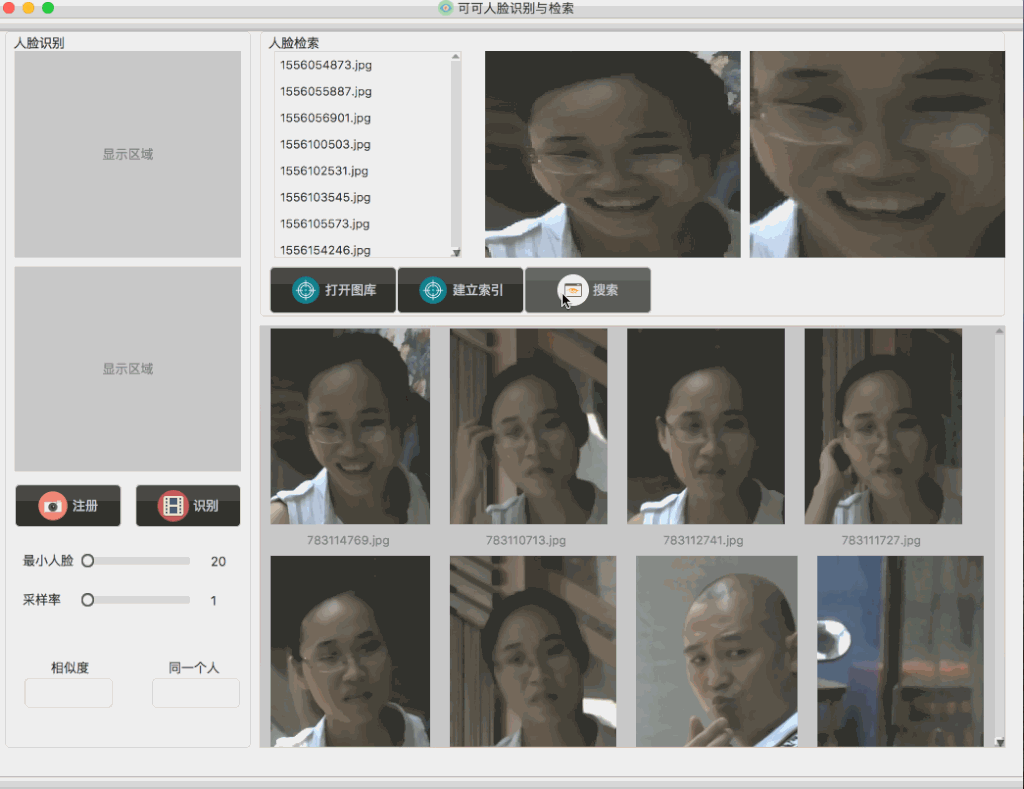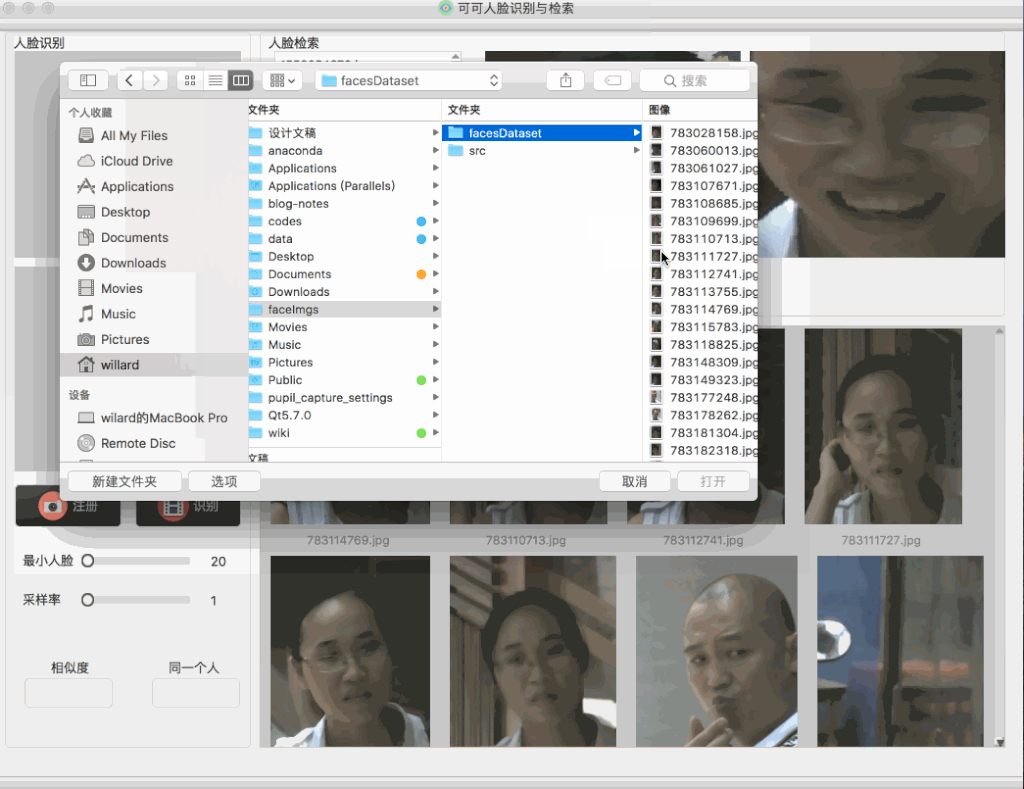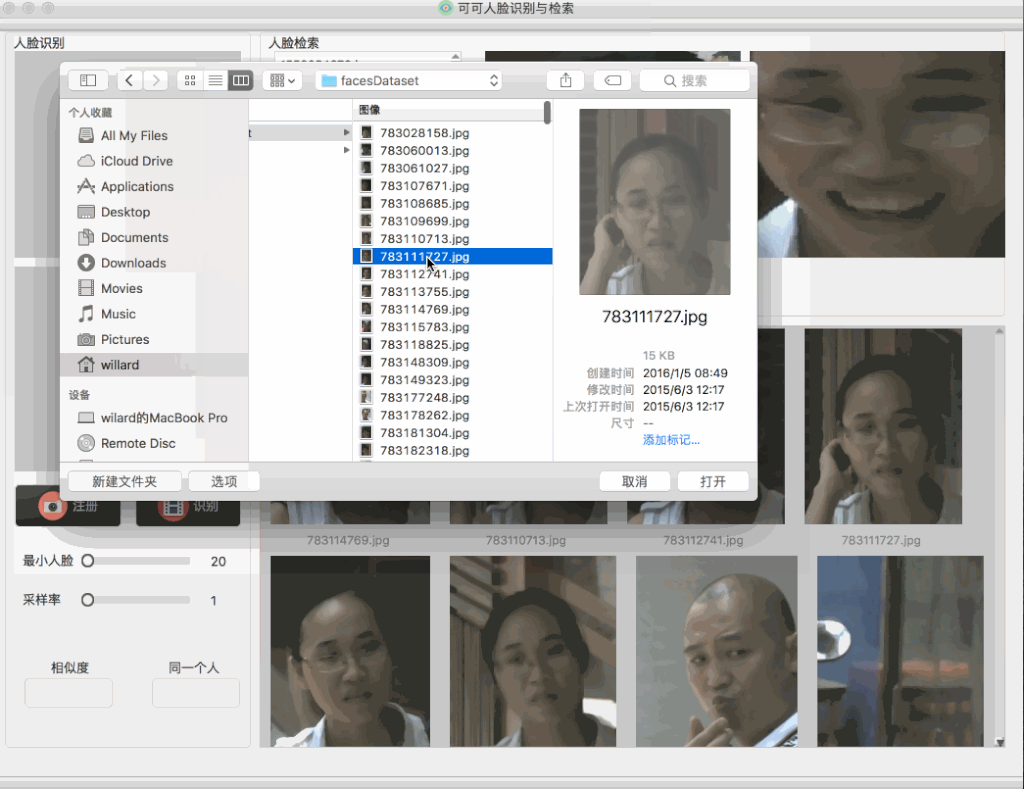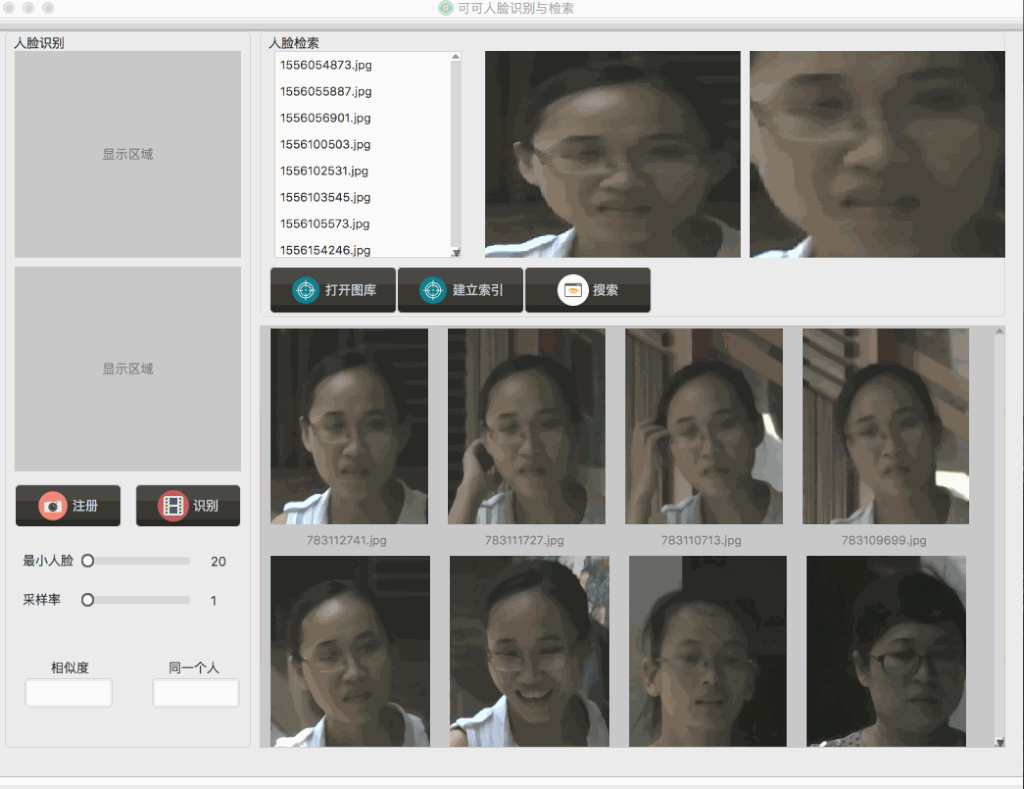
从上图可以看到,在查询的时候,会出现较长时间的卡顿现象,于是小白菜猜测,应该是线性扫描耗时过长造成的卡顿,因为在查询触发的时候,在第一次查询开启之时会读取图库特征,以后便一直保存在内存中,也就是在后面的查询中,不会再有读取图库特征这一步了。所以,对于后面的查询,时间主要消耗纯粹的相似度计算以及排序上。具体地,会先计算查询图像(在线提取查询图像的特征)的特征,然后挨个计算查询图像到图像库(特征已离线提取)中特征的余弦距离,即:
// Calculate cosine distance between query and data base faces
std::vector<std::pair<float, size_t> > dists_idxs;
int i = 0;
for(auto featItem: namesFeats.second){
// http://stackoverflow.com/questions/2923272/how-to-convert-vector-to-array-c
float tmp_cosine_dist = face_recognizer->CalcSimilarity(query_feat, &featItem[0]);
dists_idxs.push_back(std::make_pair(tmp_cosine_dist, i++));
}
在上面计算完查询特征到图库各个特征的余弦距离后,会再对计算的距离进行全局排序:
std::sort(dists_idxs.begin(), dists_idxs.end());
std::reverse(dists_idxs.begin(), dists_idxs.end());
for (size_t i = 0 ; i != dists_idxs.size() ; i++) {
//qDebug()<<dists_idxs[i].first<<namesFeats.first.at(dists_idxs[i].second).c_str();
QString tmpImgName = dir + '/' + namesFeats.first.at(dists_idxs[i].second).c_str();
imgs_listeWidget->addItem(new QListWidgetItem(QIcon(tmpImgName), QString::fromStdString(namesFeats.first.at(dists_idxs[i].second).c_str())));
}
为了进一步确认,还可以对执行的时间进行测试确认。从上面的过程可以看到,这种brute-search的方式实在是太耗时了,那么有没有方式能够缓解这种相应不够实时的问题呢。答案是有的,我们可以通过以下手段对这种brute-force search低效的方式做一些缓解:
-
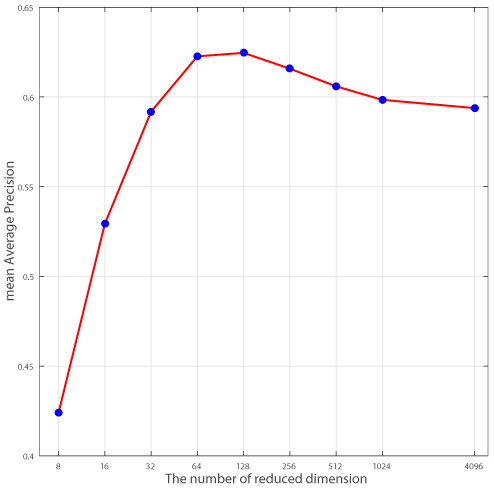
PCA降维。对于通过深度学习方式得到的特征,降维不会对信息造成大的损失,事实上在Neural codes for image retrieval这篇文章中已经指出了PCA对于深度描述子几乎不会造成损失,小白菜之前也对这样一个结论做过验证,见下图:
-
使用多线程技术。在计算余弦距离的时候,使用OpenMP多线程技术,这种方式能够较大幅度的降低搜索时间,比如CPU是8线程的,则可以将原来的时间降低为原来的8分之一。
上所列举的两种方式,能够缓解brute-force search的低效,但并不能从根本上解决索引的低效问题。因此,为了适应大规模描述子的索引,需要寻求一种合理的索引结构。目前,在近似最近邻搜索(ANN, Approximate Nearest Neighbors)方面,主要存在的方法有:
- 树结构索引方式。最经典的代表就是KD树了,小白菜用过的KD树的场合有:SIFT匹配、BoW模型。
- PQ量化以及以PQ量化进行演变的改进方法。对向量进行切分,单独做聚类进行编码。
KD树和PQ量化方式用图示意表述如下:
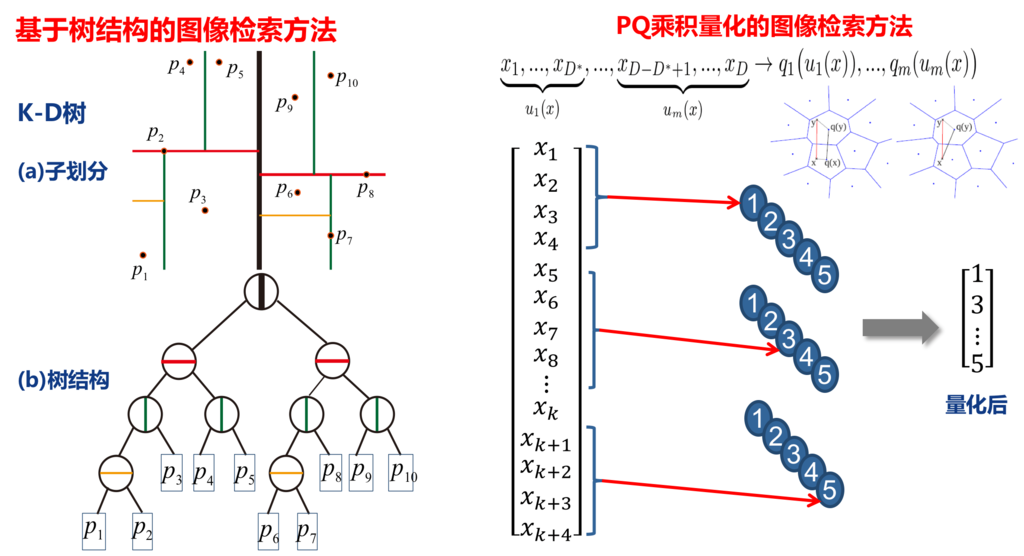 对于KD树和PQ量化方法的优缺点,可以参阅小白菜的博文图像检索:基于内容的图像检索技术。
对于KD树和PQ量化方法的优缺点,可以参阅小白菜的博文图像检索:基于内容的图像检索技术。
- 基于哈希编码编码的方式。这类方法在小白菜读书的时候,为其主要研究方向。采用哈希进行图像检索的主要思想可以用下面这种图进行示意
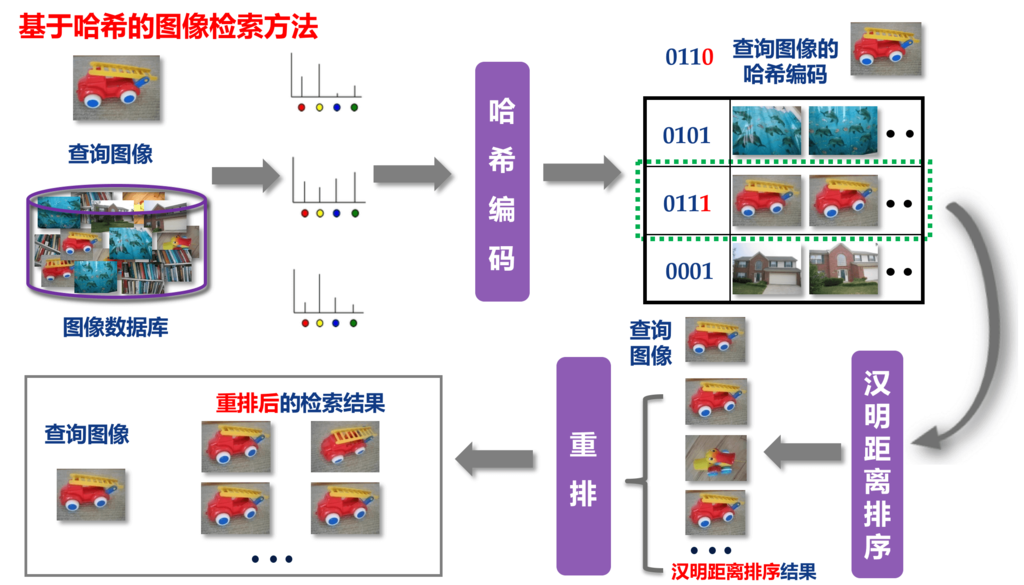
更多关于哈希方法的介绍和总结,可以参阅小白菜以前对哈希方法写的一些博文。另外,关于ANN的benchmark,可以阅读开源代码ann-benchmarks,小白菜觉得这个非常棒,果断star吖。
因而,针对上面的人脸检索,为了构建一个比较高效的索引,小白菜选用了哈希方法。当然,除了哈希方法,还可以选用PQ方法,不推荐使用KD树方法。说一下选用哈希方法的理由:看到了篇文章Practical and Optimal LSH for Angular Distance,2015年NIPS的文章,对应的开源库是Falconn,Cross-polytope LSH把LSH优化到了极致(个人读完论文的结论),此外,自己对哈希方面很熟悉,用起来应该比较顺手。其实刚开始的时候,并没有打算用LSH的,是打算用Efficient Indexing of Billion-Scale Datasets of Deep Descriptors的,正如你所看到的,连博文的标题都是为其而准备的,这篇论文小白菜详细的读过,虽然现在用的是LSH,但后面还可以继续把对应的代码读一遍。在当前这个人间检索小应用中,LSH的调用代码如下:
if(namesFeats.first.empty()){
featExtractor->loadFeaturesFilePair(namesFeats, path_namesFeats);
qDebug()<<"first loaded";
// LSH搜索方案
int numFeats = (int)namesFeats.first.size();
int dim = (int)namesFeats.second[0].size();
// Data set parameters
uint64_t seed = 119417657;
// Common LSH parameters
int num_tables = 8;
int num_setup_threads = 0;
StorageHashTable storage_hash_table = StorageHashTable::FlatHashTable;
DistanceFunction distance_function = DistanceFunction::NegativeInnerProduct;
// 转换数据类型
for (int ii = 0; ii < numFeats; ++ii) {
falconn::DenseVector<float> v = Eigen::VectorXf::Map(&namesFeats.second[ii][0], dim);
v.normalize(); // L2归一化
data.push_back(v);
}
// Cross polytope hashing
params_cp.dimension = dim;
params_cp.lsh_family = LSHFamily::CrossPolytope;
params_cp.distance_function = distance_function;
params_cp.storage_hash_table = storage_hash_table;
params_cp.k = 2; // 每个哈希表的哈希函数数目
params_cp.l = num_tables; // 哈希表数目
params_cp.last_cp_dimension = 2;
params_cp.num_rotations = 2;
params_cp.num_setup_threads = num_setup_threads;
params_cp.seed = seed ^ 833840234;
}
cptable = unique_ptr<falconn::LSHNearestNeighborTable<falconn::DenseVector<float>>>(std::move(construct_table<falconn::DenseVector<float>>(data, params_cp)));
cptable->set_num_probes(896);
qDebug() << "index build finished ...";
cptable->find_k_nearest_neighbors(q, 20, &idxCandidate);
上面代码还有很大的速度方面的优化空间,anyway,我们先暂时抛开代码的优化,来看一下改用LSH索引后的效果,下面是改用LSH后查询响应的效果:
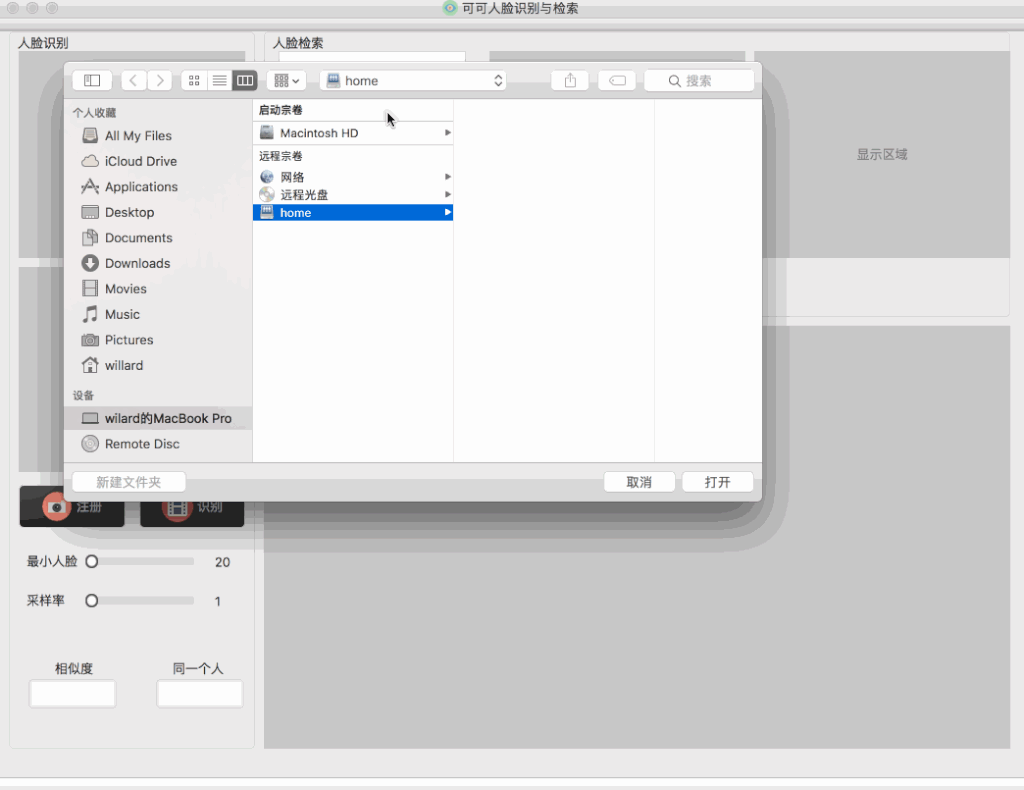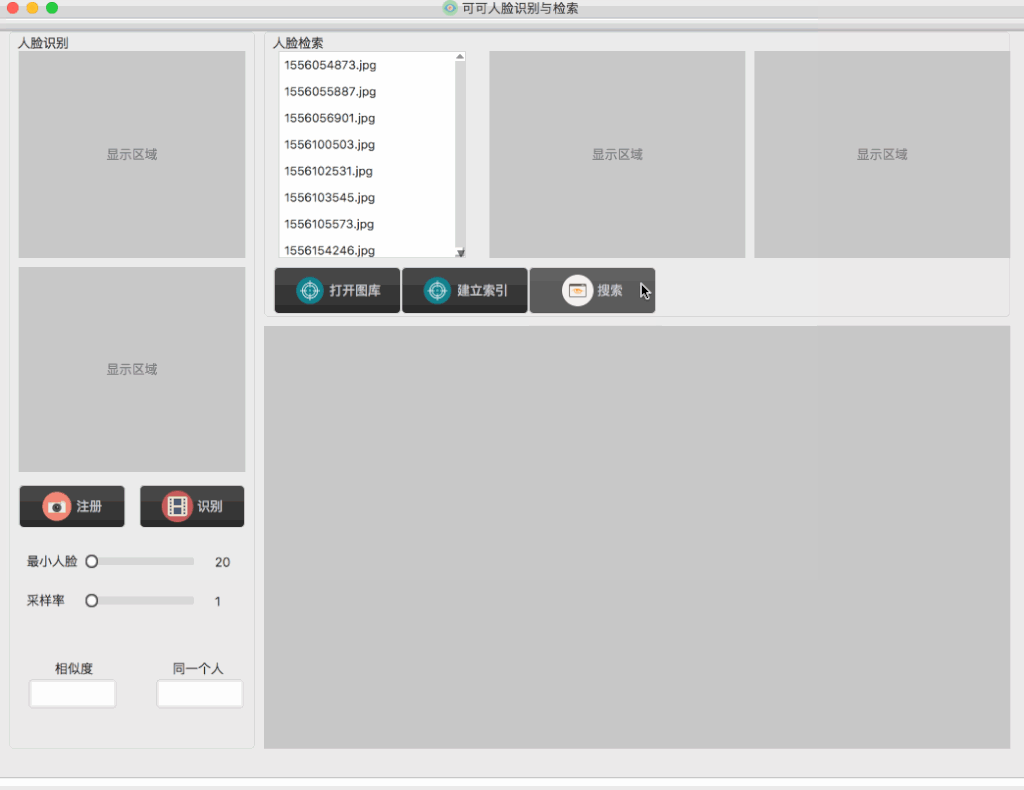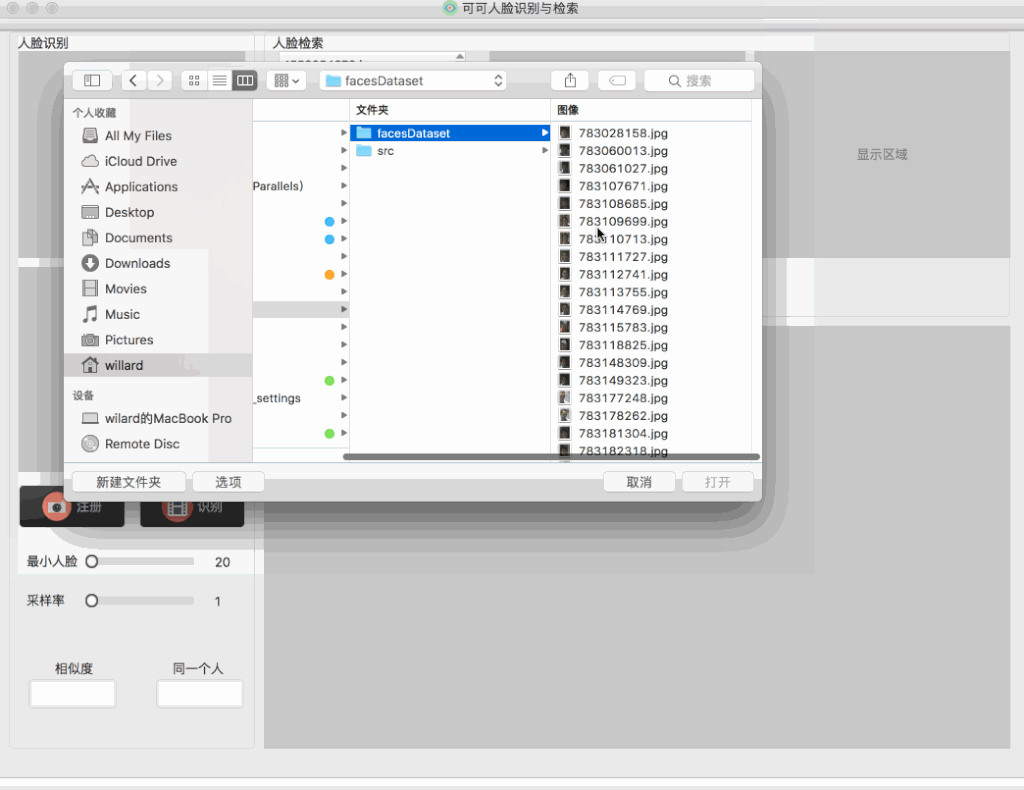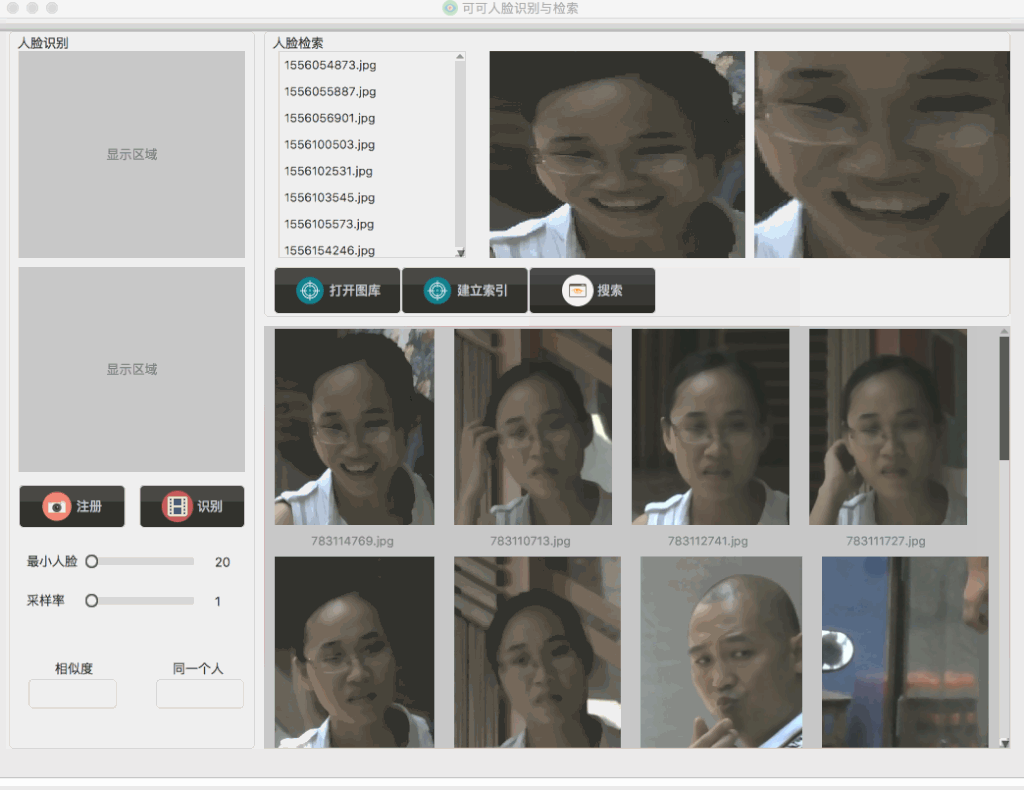 从展示的效果来看,对于查询相应的速度,有了较大的改善,但是我们还是可以看到在查询的时候,有一段空白的白板,这个问题小白菜的猜测是它应该不是由于索引慢而导致的,对于这个短时的空白白板的优化,小白菜把它放到下期进行,同时,也会对Efficient Indexing of Billion-Scale Datasets of Deep Descriptors这篇文章做一个理解总结。
从展示的效果来看,对于查询相应的速度,有了较大的改善,但是我们还是可以看到在查询的时候,有一段空白的白板,这个问题小白菜的猜测是它应该不是由于索引慢而导致的,对于这个短时的空白白板的优化,小白菜把它放到下期进行,同时,也会对Efficient Indexing of Billion-Scale Datasets of Deep Descriptors这篇文章做一个理解总结。




