
人的独立性和参与性必须适得其所,平衡发展。一方面,过分的参与必然导致远离自我核心,现代人之所以感到空虚、无聊,在很大程度上就是由于顺从、依赖和参与过多,脱离了自我核心。另一方面,过分的独立会将自己束缚在狭小的自我世界内,缺乏正常的交往,必然损害人的正常发展。
关于索引结构,有千千万万,而在图像检索领域,索引主要是为特征索引而设计的一种数据结构。关于ANN搜索领域的学术研究,Rasmus Pagh发起的大规模相似搜索项目ANN-Benchmarks、Faiss以及ann-benchmarks都有对一些主流的方法做过对比。虽然三个对比的框架对不同方法的性能均有出入,但一些主流方法的性能差异是可以达成共识的,比如基于图方法的ANN其召回率均要优于其他方法。在工业上,常用的索引方法主要以倒排、PQ及其变种、基于树的方法(比如KD树)和哈希(典型代表LSH和ITQ)为主流。关于KD树、LSH以及PQ,小白菜曾在此前的博文图像检索:再叙ANN Search已有比较详细的介绍。本文是小白菜结合实际应用,对PQ的改进方法OPQ以及基于图的方法HNSW的理解,以及关于索引的一些总结与思考。
OPQ vs. HNSW
首先从检索的召回率上来评估,基于图的索引方法要优于目前其他一些主流ANN搜索方法,比如乘积量化方法(PQ、OPQ)、哈希方法等。虽然乘积量化方法的召回率不如HNSW,但由于乘积量化方法具备内存耗用更小、数据动态增删更灵活等特性,使得在工业检索系统中,在对召回率要求不是特别高的场景下,乘积量化方法仍然是使用得较多的一种索引方法,淘宝(详见Fast Approximate Nearest Neighbor Search With The Navigating Spreading-out Graph)、蘑菇街等公司均有使用。乘积量化和HNSW特性对比如下:
| 特性 | OPQ | HNSW |
|---|---|---|
| 内存占用 | 小 | 大 |
| 召回率 | 较高 | 高 |
| 数据动态增删 | 灵活 | 不易 |
基于图ANN方法由于数据在插入索引的时候,需要计算(部分)数据间的近邻关系,因而需要实时获取到到数据的原始特征,几乎所有基于图ANN的方法在处理该问题的时候,都是直接将原始特征加载在内存(索引)里,从而造成对内存使用过大,至于召回率图ANN方法要比基于量化的方法要高,这个理解起来比较直观。下面分别对改进的乘积量化方法OPQ以及基于图ANN方法HNSW做原理上的简要介绍。
OPQ
OPQ是PQ的一种改进方法,关于PQ的介绍,在此前的文章图像检索:再叙ANN Search中已有详细介绍,这里仅对改进的部分做相应的介绍。
通常,用于检索的原始特征维度较高,所以实际在使用PQ等方法构建索引的时候,常会对高维的特征使用PCA等降维方法对特征先做降维处理,这样降维预处理,可以达到两个目的:一是降低特征维度;二是在对向量进行子段切分的时候要求特征各个维度是不相关的,做完PCA之后,可以一定程度缓解这个问题。但是这么做了后,在切分子段的时候,采用顺序切分子段仍然存在一定的问题,这个问题可以借用ITQ中的一个二维平面的例子加以说明:
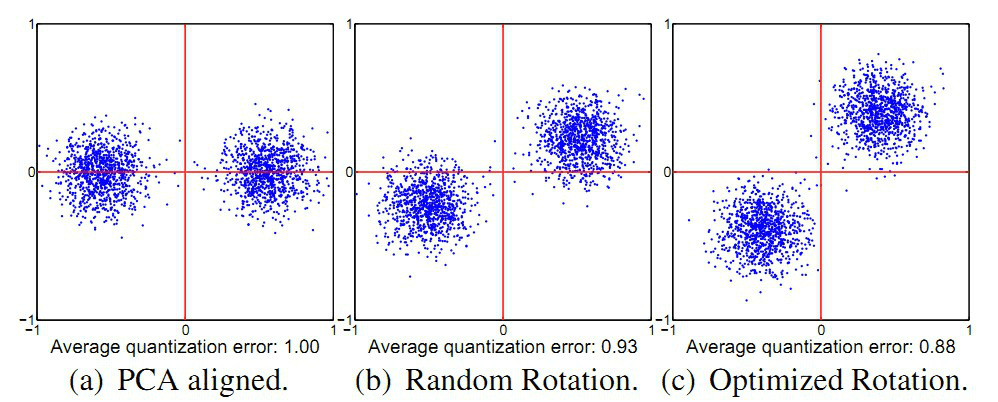
如上面左图(a图)所示,对于PCA降维后的二维空间,假设在做PQ的时候,将子段数目设置为2段,即切分成$x$和$y$两个子向量,然后分别在$x$和$y$上做聚类(假设聚类中心设置为2)。对左图(a图)和右图(c图)聚类的结果进行比较,可以明显的发现,左图在y方向上聚类的效果明显差于右图,而PQ又是采用聚类中心来近似原始向量(这里指降维后的向量),也就是右图是我们需要的结果。这个问题可以转化为数据方差来描述:在做PQ编码时,对于切分的各个子空间,我们应尽可能使得各个子空间的方差比较接近,最理想的情况是各个子空间的方差都相等。上图左图中,$x$和$y$各个方向的方差明显是差得比较大的,而对于右图,$x$和$y$方向各个方向的方差差不多是比较接近的。
为了在切分子段的时候,使得各个子空间的方差尽可能的一致,Herve Jegou在Aggregating local descriptors into a compact image representation中提出使用一个正交矩阵来对PCA降维后的数据再做一次变换,使得各个子空间的方差尽可能的一致。其对应的待优化目标函数见论文的第5页,由于优化该目标函数极其困难,Herve Jegou使用了Householder矩阵来得到该正交矩阵,但是得到的该正交矩阵并不能很好的均衡子空间的方差。
OPQ致力于解决的问题正是对各个子空间方差的均衡。具体到方法上,OPQ借鉴了ITQ的思想,在聚类的时候对聚类中心寻找对应的最优旋转矩阵,使得所有子空间中各个数据点到对应子空间的类中心的L2损失的求和最小。OPQ在具体求解的时候,分为非参求解方法和带参求解方法,具体为:
- 非参求解方法。跟ITQ的求解过程一样。
- 带参求解方法。带参求解方法假设数据服从高斯分布,在此条件下,最终可以将求解过程简化为数据经过PCA分解后,特征值如何分组的问题。在实际中,该解法更具备高实用性。
HNSW
HNSW是Yury A. Malkov提出的一种基于图索引的方法,它是Yury A. Malkov在他本人之前工作NSW上一种改进,通过采用层状结构,将边按特征半径进行分层,使每个顶点在所有层中平均度数变为常数,从而将NSW的计算复杂度由多重对数(Polylogarithmic)复杂度降到了对数(logarithmic)复杂度。
贡献
- 图输入节点明确的选择
- 使用不同尺度划分链接
- 使用启发式方式来选择最近邻
近邻图技术
对于给定的近邻图,在开始搜索的时候,从若干输入点(随机选取或分割算法)开始迭代遍历整个近邻图。
在每一次横向迭代的时候,算法会检查链接或当前base节点之间的距离,然后选择下一个base节点作为相邻节点,使得能最好的最小化连接间的距离。
近邻图主要的缺陷:1. 在路由阶段,如果随机从一个或者固定的阶段开始,迭代的步数会随着库的大小增长呈现幂次增加;2. 当使用k-NN图的时候,一个全局连接可能的损失会导致很差的搜索结果。
算法描述
网络图以连续插入的方式构建。对于每一个要插入的元素,采用指数衰变概率分布函数来随机选取整数最大层。

- 图构建元素插入过程(Algorithm 1):从顶层开始贪心遍历graph,以便在某层A中找到最近邻。当在A层找到局部最小值之后,再将A层中找到的最近邻作为输入点(entry point),继续在下一层中寻找最近邻,重复该过程;
- 层内最近邻查找(Algorithm 2):贪心搜索的改进版本;
- 在搜索阶段,维护一个动态列表,用于保持ef个找到的最近邻元素
在搜索的初步阶段,ef参数设置为1。搜索过程包括zoom out和zoom in两个阶段,zoom out是远程路由,zoom in顾名思义就是在定位的区域做精细的搜索过程。整个过程可以类比在地图上寻找某个位置的过程:我们可以地球当做最顶层,五大洲作为第二层,国家作为第三层,省份作为第四层……,现在如果要找海淀五道口,我们可以通过顶层以逐步递减的特性半径对其进行路由(第一层地球->第二层亚洲—>第三层中国->第四层北京->海淀区),到了第0层后,再在局部区域做更精细的搜索。
数据实验说明
199485332条人脸数据(128维,L2归一化)作为database, 10000条人脸数据作为查询。gound truth由暴力搜索结果产生(余弦相似度),将暴力搜索结果的rank@1作为gound truth,评估top@K下的召回率。
实验结果与调优
M参数:80,内存大小: 159364 Mb,索引文件:cnn2b_199485332m_ef_80_M_32_ip.bin,查询样本数目: 10000,ef: 1000,距离:内积距离
| top@K | 召回 | 时间(time(us) per query) |
|---|---|---|
| 1 | 0.957000 | - |
| 2 | 0.977300 | 9754.885742us |
| 3 | 0.981200 | 9619.380859us |
| 4 | 0.983100 | 9652.819336us |
| 5 | 0.983800 | 9628.488281us |
| 10 | 0.984500 | 9650.678711us |
| 50 | 0.986400 | 9647.286133us |
| 100 | 0.986700 | 9665.638672us |
| 300 | 0.987000 | 9685.414062us |
| 500 | 0.987100 | 9744.437500us |
| 1000 | 0.987100 | 9804.702148us |
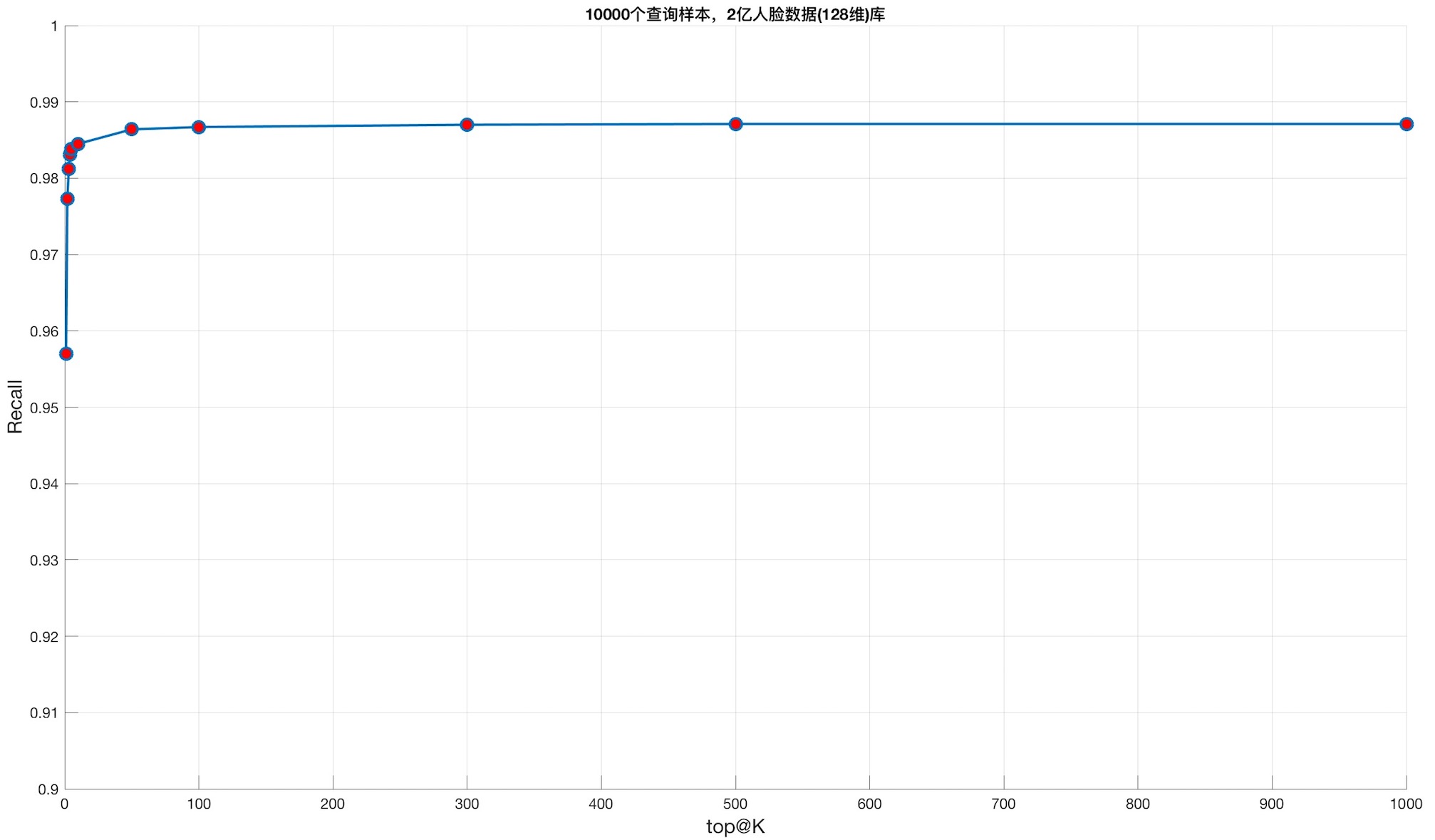
M参数:16,Mem: 173442 Mb, 索引文件:cnn2b_199485332m_ef_40_M_16.bin, 查询样本数目: 10000,ef: 1000,距离:欧氏距离
| top@K | 召回 | 时间(time_us_per_query) |
|---|---|---|
| 1 | 0.887800 | 4845.700684us |
| 2 | 0.911700 | 6732.230957us |
| 3 | 0.916600 | 6879.585449us |
| 4 | 0.917500 | 6963.914062us |
| 5 | 0.918000 | 6920.318359us |
| 10 | 0.920200 | 6880.795898us |
| 50 | 0.922400 | 6900.778809us |
| 100 | 0.923000 | 6970.664062us |
| 300 | 0.923400 | 6978.517578us |
| 500 | 0.923400 | 6992.306152us |
M参数:40,Mem: 211533 Mb, 索引文件:cnn2b_199485332m_ef_40_M_40.bin, 查询样本数目: 10000,ef: 1000,距离:内积距离
| top@K | 召回 | 时间(time_us_per_query) |
|---|---|---|
| 1 | 0.928600 | 6448.714355us |
| 2 | 0.948300 | 7658.459961us |
| 3 | 0.952600 | 7674.244629us |
| 4 | 0.954000 | 7659.506348us |
| 5 | 0.954700 | 7679.874023us |
| 10 | 0.955800 | 7709.812500us |
| 50 | 0.957400 | 7720.283691us |
| 100 | 0.957800 | 7722.512695us |
| 300 | 0.958000 | 7763.615234us |
| 500 | 0.958100 | 7779.351562us |
| 1000 | 0.958100 | 7859.372559us |
余弦相似度与余弦距离关系
Supported distances:
| Distance | parameter | Equation |
|---|---|---|
| Squared L2 | ‘l2’ | d = sum((Ai-Bi)^2) |
| Inner product | ‘ip’ | d = 1.0 - sum(Ai*Bi)) |
| Cosine similarity | ‘cosine’ | d = 1.0 - sum(Ai*Bi) / sqrt(sum(Ai*Ai) * sum(Bi*Bi)) |
参数说明
- efConstruction:设置得越大,构建图的质量越高,搜索的精度越高,但同时索引的时间变长,推荐范围100-2000
- efSearch:设置得越大,召回率越高,但同时查询的响应时间变长,推荐范围100-2000,在HNSW,参数ef是efSearch的缩写
- M:在一定访问内,设置得越大,召回率增加,查询响应时间变短,但同时M增大会导致索引时间增加,推荐范围5-100
HNSW L2space返回的top@K,是距离最小的K个结果,但是在结果表示的时候,距离是从大到小排序的,所以top@K距离是最小的,top@K-1距离是次之,top@1是距离第K大的。只是结果在表示上逆序了而已,不影响最终的结果。如果要按正常的从小到大来排序,则对top@K的结果做个逆序即可。作者在python的接口里,实现了这种逆序,具体见bindings.cpp#L287,所以python的结果和c++的结果,是逆序的差异。
参数详细意义
-
M:参数M定义了第0层以及其他层近邻数目,不过实际在处理的时候,第0层设置的近邻数目是2*M。如果要更改第0层以及其他层层近邻数目,在HNSW的源码中进行更改即可。另外需要注意的是,第0层包含了所有的数据点,其他层数据数目由参数mult定义,详细的细节可以参考HNSW论文。
- delaunay_type:检索速度和索引速度可以通过该参数来均衡heuristic。HNSW默认delaunay_type为1,将delaunay_type设置为1可以提高更高的召回率(> 80%),但同时会使得索引时间变长。因此,对于召回率要求不高的场景,推荐将delaunay_type设置为0。
- post:post定义了在构建图的时候,对数据所做预处理的数量(以及类型),默认参数设置为0,表示不对数据做预处理,该参数可以设置为1和2(2表示会做更多的后处理)。
更详细的参数说明,可以参考parameters说明。
demo
小白菜基于局部特征,采用HNSW做过一版实例搜索,详细说明详见HNSW SIFTs Retrieval。适用范围:中小规模。理论上,直接基于局部特征索引的方法,做到上千万级别的量级,是没有问题的,成功的例子详见videntifier,Herwig Lejsek在设计videntifier系统的时候,使用的是NV-Tree,每一个高维向量只需用6个字节来表示,压缩比是非常大的,(O)PQ折中情况下一般都需要16个字节。关于NV-Tree的详细算法,可以阅读Herwig Lejsek的博士论文NV-tree: A Scalable Disk-Based High-Dimensional Index,墙裂推荐一读。
总结
在本篇博文里,小白菜对图ANN、基于量化的两类方法分别选取了最具代表性的方法HNSW和OPQ方法进行比较详细的总结,其中由以基于PQ的量化方法在工业界最为实用,基于图的ANN方法,在规模不是特别大但对召回要求非常高的检索场景下,是非常适用的。除此之外,图ANN方法可以和OPQ结合起来适用,来提高OPQ的召回能力,具体可以阅读Revisiting the Inverted Indices for Billion-Scale Approximate Nearest Neighbors和Link and code: Fast indexing with graphs and compact regression codes这两篇文章。




