
BoW (Bag of visual word)、VLAD (Aggregating local descriptors)以及Fisher Vector (Fisher Vector)是三种非常经典的将局部特征表示成全局特征的编码方法,在图像检索领域,这图像检索领域,这三种编码方法是必须面对的三名剑客。下面是小白菜结合自己的理解,对这三种编码方法的原理和一些实践经验的总结。
BoF词袋模型
基于SIFT局部特征的BOF模型非常适合于做Object retrieval, 下面是自己在oxford building数据库(5063张图片)上进行的一些实验。表格中单词数目为聚类时设定的聚类数目,以及是否采用SIFT或者rootSIFT,rootSIFT怎么计算的可以阅读Object retrieval with large vocabularies and fast spatial matching这篇文章,空间校正即在重排的时候,对错配的SIFT点对进行剔除,剔除的方法可以采用RANSAC或者类RANSAC方法,详细介绍可以阅读SIFT(ASIFT) Matching with RANSAC,检索精度采用平均检索精度(mean Average Precision, mAP),其计算过程可以阅读信息检索评价指标这篇文章。下面需要注意的是查询时间单次查询的结果,并没有进行多次查询进行平均,此外查询时间是查询和计算mAP时间的总和。
- 单词数目为100k统计的各项指标。单词数目设置为100k,采用rootSIFT,依次对不同重排深度统计其mAP,其中查询时间只是作为一个参考,注意当重排深度为1时,其结果与不重排的mAP是一样的。
| 单词数目 | SIFT or rootSIFT | 空间校正与否 | 重排数目 | 检索精度mAP | 查询时间(55张)(s) |
|---|---|---|---|---|---|
| 100k | rootSIFT | 否 | - | 62.46% | 5.429707 |
| 100k | rootSIFT | 是 | 20 | 66.42% | 20.853832 |
| 100k | rootSIFT | 是 | 30 | 68.25% | 21.673585 |
| 100k | rootSIFT | 是 | 40 | 69.27% | 23.300404 |
| 100k | rootSIFT | 是 | 50 | 69.83% | 23.719468 |
| 100k | rootSIFT | 是 | 100 | 72.48% | 24.180888 |
| 100k | rootSIFT | 是 | 200 | 75.56% | 31.165427 |
| 100k | rootSIFT | 是 | 500 | 78.85% | 46.064313 |
| 100k | rootSIFT | 是 | 1000 | 79.93% | 70.192928 |
| 100k | rootSIFT | 是 | 2000 | 80.75% | 110.999173 |
| 100k | rootSIFT | 是 | 3000 | 80.92% | 145.799017 |
| 100k | rootSIFT | 是 | 4000 | 80.97% | 176.786657 |
| 100k | rootSIFT | 是 | 5063 | 80.96% | 207.201570 |
从上表可以看出,对结果进行重排后,其mAP会得到明显的提高,但并不是说重排深度越深越好,可以看到从重排深度为1000开始,在随着重排深度的增加,其提升得已经非常小了,不仅如此,其耗费的查询时间越来越长。
- 单词数目为500k时统计的各项指标。同样进行如上说明的指标统计,这里单词数目加大为500k。
| 单词数目 | SIFT or rootSIFT | 空间校正与否 | 重排数目 | 检索精度mAP | 查询时间(55张)(s) |
|---|---|---|---|---|---|
| 500k | rootSIFT | 否 | - | 74.82% | 5.345534 |
| 500k | rootSIFT | 是 | 20 | 77.77% | 21.646773 |
| 500k | rootSIFT | 是 | 30 | 79.06% | 21.615220 |
| 500k | rootSIFT | 是 | 40 | 79.86% | 23.453462 |
| 500k | rootSIFT | 是 | 50 | 80.54% | 23.588034 |
| 500k | rootSIFT | 是 | 100 | 82.18% | 24.942057 |
| 500k | rootSIFT | 是 | 200 | 83.35% | 30.585792 |
| 500k | rootSIFT | 是 | 500 | 84.89% | 41.023239 |
| 500k | rootSIFT | 是 | 1000 | 85.52% | 54.836481 |
| 500k | rootSIFT | 是 | 2000 | 85.73% | 67.173112 |
| 500k | rootSIFT | 是 | 3000 | 85.77% | 80.634803 |
| 500k | rootSIFT | 是 | 5063 | 85.76% | 103.606303 |
- 单词数目为1M时统计的各项指标。这里我把单词数目设为了1M(已经非常大了),在聚类阶段,其时间相比于前面的,所用时间更长,在服务器上跑大概用了二十几个小时。
| 单词数目 | SIFT or rootSIFT | 空间校正与否 | 重排数目 | 检索精度mAP | 查询时间(55张)(s) |
|---|---|---|---|---|---|
| 1M | rootSIFT | 否 | - | 77.64% | 5.513093 |
| 1M | rootSIFT | 是 | 20 | 80.00% | 18.864077 |
| 1M | rootSIFT | 是 | 30 | 80.81% | 18.948402 |
| 1M | rootSIFT | 是 | 40 | 81.44% | 21.543470 |
| 1M | rootSIFT | 是 | 50 | 82.02% | 23.290658 |
| 1M | rootSIFT | 是 | 100 | 83.32% | 25.396074 |
| 1M | rootSIFT | 是 | 200 | 84.47% | 31.414361 |
| 1M | rootSIFT | 是 | 500 | 85.25% | 39.314887 |
| 1M | rootSIFT | 是 | 1000 | 85.51% | 46.913126 |
| 1M | rootSIFT | 是 | 2000 | 85.55% | 58.102913 |
| 1M | rootSIFT | 是 | 3000 | 85.55% | 68.756579 |
| 1M | rootSIFT | 是 | 4000 | 85.55% | 77.051332 |
| 1M | rootSIFT | 是 | 5063 | 85.55% | 85.428169 |
可以看到,其进行全部重排的时候的精度,相比于500k的,并没有得到提升,为了更清楚的看到在不同单词数目其对精度的影响,我把三种统计下的结果画成了曲线,如下图示:
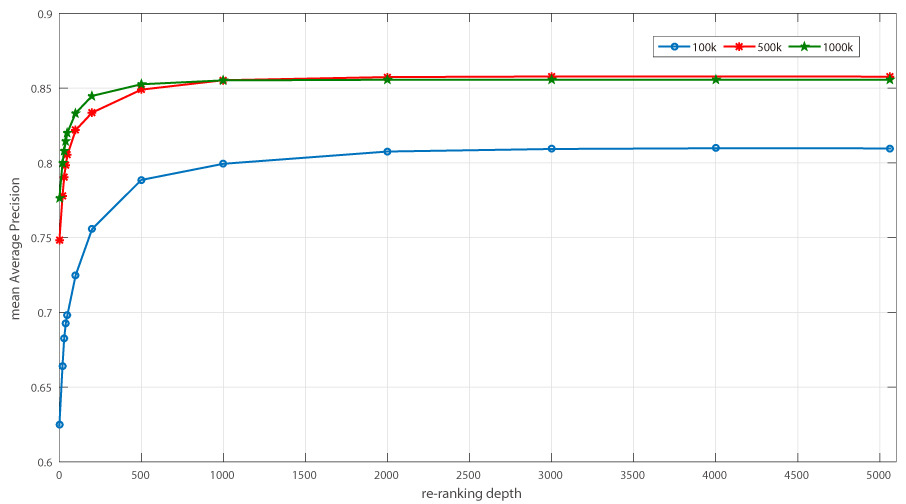
从上图可以看到,在一定范围内,在相同的重排深度下,单词数目越大,其mAP会越高,注意是在一定范围内,当超过了某个范围,其mAP并不会得到明显的提高了,比如500k和1M,从重排深度为500开始,其精度几乎一样了,这告诉我们,并不是说单词数目设得越大越好,我们应该通过实验测试选择出一个合理的单词数目,这样可以避免过量的计算以及存储空间的消耗。同样,在选择重排深度时,也并不是越大越好,我们应该选择那些在平滑转角过渡的重排深度比较合理,这里,比较好的方案是单词数目选择500k,重排深度设置为500。
同样,俺也把100k,500k,1M下单词下查询时间做了一张图,需要注意的是,纵轴的时间是对55张查询图像总时间的平均:
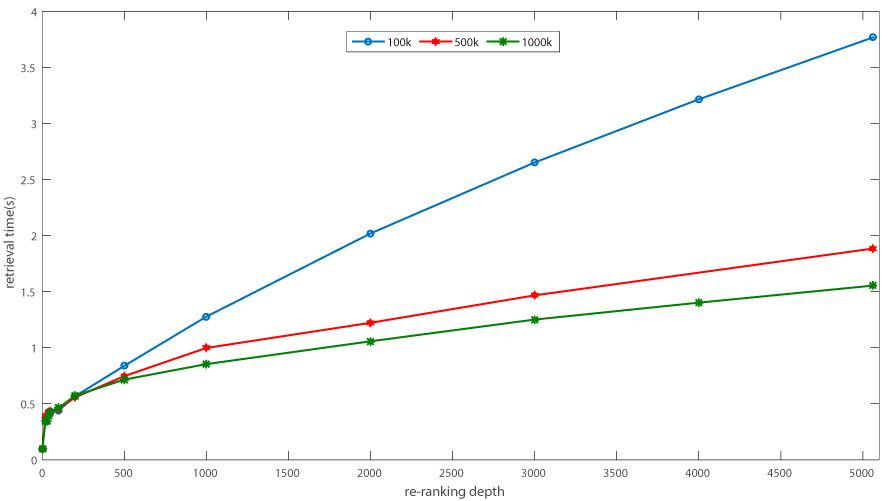
上图显示统计的查询时间很怪异,因为随着单词数目的增加,其查询时间应该会越来越长的,但是这里得出的确实越来越短,这里可能的原因是服务器很多人在用,并不满足单一条件在变化的环境,所以所以这里的时间只是作为一个对查询时间的参考,并不能反映理论上的时间变化趋势。
正如标题所示,这里将记录VLAD的一切。VLAD本小子虽然也读过几篇这方面的paper,不过读的时候一直理解的很粗糙。所以想借此机会开个帖子,一方面驱动自己去加深对它的理解,另一方面把这些自己对它的理解记录下来,方便自己查阅。
VLAD局部聚合向量
在进行理论分析之前,先来看看VLAD长个什么样子,这里本小子分步展开VLAD是怎么得来的。
- 提取SIFT特征。对于一个样本数为N的数据库,先对图像库中的所有图像提取SIFT描述子,假设提取到了所有SIFT描述子数目为n,用X来表示的话,X就是一个n*128的矩阵。
- 聚类生成词汇向量。假设要生成K个单词,对X直接用Kmeans聚成K类,类中心即为单词(也叫码字)。
- 生成VLAD向量。这一步其实如果对BOW的生成过程清楚的话,这一步理解起来就非常简单了。BoW统计的是描述子落入最近单词里的数目,而VLAD统计的则是这些落入最近单词里与该单词的累积残差。根据Aggregating local image descriptors into compact codes的描述:
By counting the number of occurrences of visual words, BOW encodes the 0-order statistics of the distribution of descriptors. The Fisher vector extends the BOW by encoding high-order statistics (first and, optionally, second order).
BOW做的是描述子的0阶统计分布,而FV则是扩展了的BOW的高阶统计。这里引出来的FV是什么呢?VLAD是FV的特例,这里我们先不关注FV,我们只要借此推得VLAD是BOW的高阶统计就行。
经过上面三个步骤后,一幅图像可以用一个1(K128)维的向量表示。为了初步验证上面的过程是否正确,来看看上面那篇论文中VLAD的维数是否如这里所理解的是一个1(K128)维的向量,直接看实验表:
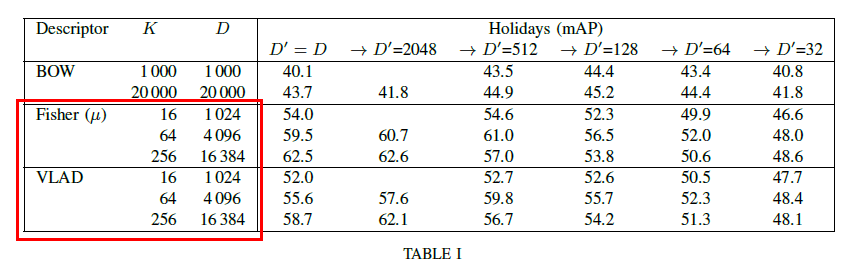
上表中FV和VLAD的D表示维数,我们看到D=K*64,这里为什么不是128呢?原因在于作者对SIFT进行了PCA降维处理,将128维降到了64维。
上面VLAD生成过程用文字描述起来不够简洁,直接把论文里计算VLAD的算法流图扒过来了,算法流图如下:

提取VLAD特征
对VLAD有了初步的认识后,接下来我们可以动手提取VLAD,通过实验来进一步了解VLAD的特性。这里我们可以直接调用INRIA开发的Yael工具包,该工具包提供了BoW、VALD以及FV的接口。为了更好的理解VALD编码的过程,可以打开Yael的vlad.c文件,其中有vlad_compute方法:
void vlad_compute(int k, int d, const float *centroids,
int n, const float *v, float *desc)
{
int i,j;
int *assign = ivec_new (n);
nn (n, k, d, centroids, v, assign);
fvec_0 (desc, k * d);
for (i = 0 ; i < n ; i++) {
for (j = 0 ; j < d ; j++)
desc[assign[i]*d+j] += v[i*d+j] - centroids[assign[i]*d+j];
}
free(assign);
}
上面清楚的显示了得到的desc(即VLAD特征表示)为距离类中心最近的局部特征的累积和,其中方法nn是做最近邻查找。有了这个接口后,我们要做的就是提取局部特征,比如SIFT,然后使用Yael里提供的KMeans接口做聚类,得到聚类中心,然后调用该函数,即可得到VLAD特征表示。
MSER
MSER得到椭圆区域后,再结合SIFT,可以剔除掉很多没用的点,VLFeat中的MESR例子见这里。此外MSER还可以用于文本区域筛选中,具体可以看这个Robust Text Detection in Natural Scenes and Web Images。概念与作用相关词:漫水填充法、显著性。
基于SIFT特征点匹配
SIFT on GPU (SiftGPU), works for nVidia, ATI and Intel cards.
Fisher Vector
| 单词数目 | 128 to 64 | 检索精度mAP |
|---|---|---|
| 256 | 是 | 42.70% |
| 512 | 是 | 52.27% |
| 1024 | 是 | 56.26% |
| 2048 | 是 | 58.68% |
| 4096 | 是 | 62.37% |
| 8192 | 是 | 65.43% |
| 10000 | 是 | 66.88% |
| 20000 | 是 | 69.61% |
- Fisher Vector 512个单词,128降维到64,oxford building上mAP为52.27%;L2归一化中如果不采用max的方式,mAP为43.43%。
- Fisher Vector 1024个单词,128降维到64,oxford building上mAP为56.26%;L2归一化中如果不采用max的方式,mAP为47.06%。
具体场景应用
上面的分析选得过于理论,实际上,我也很希望做的这些东西能够在实际的场景进行测试,下面对自己遇到的实际场景(这些应用主要还是帮别人做的测试)做尽可能多的总结,虽然有些做的东西已经被我删掉了,但本小子还是希望有机会能够一一把它们补全。
商品搜索
“商品”是一个很泛的词,只要拿去交易的东西,都可以成为商品,不过具体到图像搜索应用这里,我还是结果自己做过的,给“商品”几种类别,目前做过的和比较了解的,主要是衣服、鞋子、书的封皮。前面两种物品,我自己亲自测试过,书籍封皮的搜索,跟做这类产品的公司负责人电话聊过。下面分别对它们进行展开。
翻拍图像搜索
这个项目主要是针对翻拍的图像进行的搜索,规模大概十万来张,整个系统要做成嵌入式的。图像检索算法设计方面,考虑到翻拍的图片会有较大的旋转、角度、光照强大(光线比较暗)变化,选用基于SIFT局部特征的方法比较适合,于是对合作方发过来的图像库用上面的方法做了相应的测试,搜索的效果比较理想,能够获得合作方对检索精度的要求。在合作方发来的图像库上做测试,检索效果比较理想。
目前存在的难点是:1. 转成C++过程各模块基本成型,但其中某些核心模块还需要耗费很多的时间去调试;2. 嵌入到硬件里过程中出现的很多不需要在服务器上考虑的问题,比较搜索时间,存储空间,怎么转成纯C方面烧写到硬件上。
图标去重
这个是有客官碰到了这么一个问题,然后邮件问本小子,大概是把APP图标去重转成了图像搜索的问题,具体的任务我也不是很清楚,然后我就给他做了测试。在看了他发过来的APP图标库后,我想这个应该用最基本的特征应该就能解决得比较好,比如颜色,因为同款的APP图标要么就是分辨率存在差异,要么是APP图标有的加了字。
![]()
总体而言,差异应该是很小的,用颜色就能够解决得很好,不过这个方案我没测试,直接用的是我上面的现成方案。之所以这么直接用,是因为这个也是做的同款任务的搜索,SIFT很适合而且很擅长做这个,只不过有可能碰到的问题是,由于APP图像分辨率太小,可能导致检测的SIFT特征点很少,会对检索的精度造成较大的影响,实验中在提取SIFT特征的时候,也确实是这样的,有的APP提取到的SIFT只有几个,不过最后做出来的效果还是比较好的。我在猜测,用颜色特征做的话,可能比这个的效果会差点。下面是部分检索可视化结果(只放两张,是在太多了,就不一一放出来了):

对于上图,如果图库比较大的话,用颜色特征可能对第二行要找的同款可能稍微有点吃力,我们再来看看下面这种情况:

对于这种情况,用颜色特征,就非常吃力了,因为后边绿色的“爸爸去哪儿”跟前面查询图像的颜色直方图会相差很大,如果从这一点看,在APP图标搜索上,颜色似乎也不是一个很好的特征,不过还是要做一下全部的查询,然后看看平均检索精度如何。
人脸搜索
待补充
模具图像搜索
这个是最近给人测的一个任务,在这个任务中既要做同款搜索,又要做同类搜索。对方在开发初期,大概跟对方的算法工程师聊了下,感觉对方在采用哪种方法去完成这个任务上经验不足和积累不足,anyway,我还是给对方免费提供了可行的方案,并对方案做了相应的验证。回到前面提到的两个需求,一是要能搜索同款模具,二是相似的模具也应该搜索到。在对方法进行设计时,最理想的方法是存在某种检索方法,使得搜索到的最前面的一些图像是同一模具,而紧随后面的图像则是跟查询图像具有相似外观的一些模具图像。具体可以看一下图像库中的一些图例:
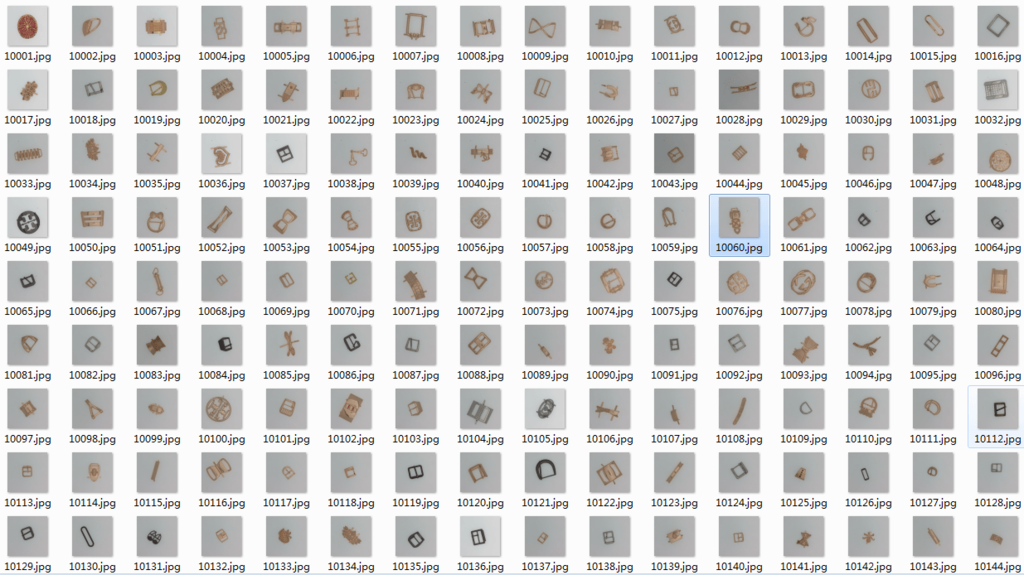
可以看到图库中模具变化还是比较大的,在对方提出需要搜索相同的模具时,我想到的方法是这个用上面的词袋模型应该会觉得得比较好,因为SIFT对于物体的旋转、光照、尺度变化等都有很好的抗干扰性,所以用上面的框架做了一些测试,下面是测试的某个查询结果:
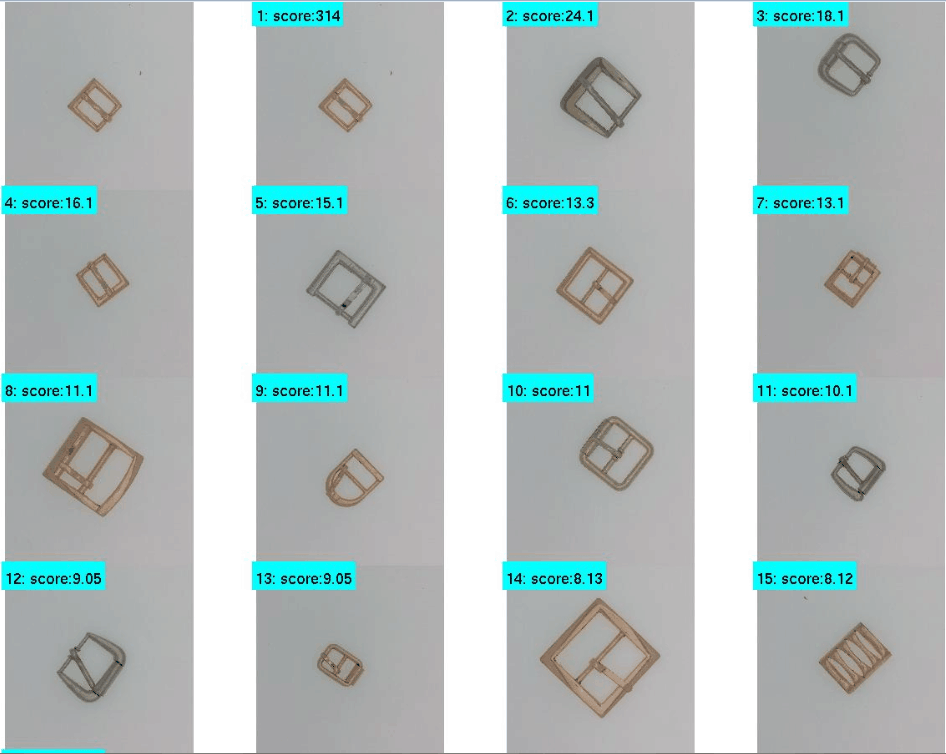
从上面可以看到,对该幅图像的查询其查询结果是让人比较满意的,第2行第1列的那幅图像稍微靠后,不过我觉得不影响使用,后面的结果也差不多都是这一类的小物品,我们再来看看另外一幅图像的查询结果:

相比于上面查询的腰带扣环图像,这里查询的这个物品其结果看上去比较糟糕,之所以呈现这样的查询结果,主要是人家发过来的图像库里腰带扣环很多,而其他的包括外形等看上去都非常的不同类,所以搜索到的结果看上去比较糟糕了。
上面分析完相同物体的检索后,我们在回过来总结一下词袋模型的特点,采用基于SIFT特征的词袋模型,虽然能够部分处理相似检索的问题,但它更适合于相同物体的搜索。如果要能够比较好的解决相似搜索的任务,CNN卷积网络更适合处理这类任务,这也可以从词袋模型和CNN模型在分类取得的精度上可以验证,CNN的分类精度要比词袋模型的分类精度高得多,说明CNN更能捕获到区分不同类样本的可区分性特征,而极大的保持了同类样本所具有的共性特征。此外,因为这些图片的背景非常的纯净,所以用CNN做相似搜索应该是一种很好的方案,由于手头没有足够的样本,我就直接用imageNet训练好的模型做测试了,用我早先写的CNN-for-Image-Retrieval做验证,下面是其中两幅图像做的查询,查询图像1如下图所示:

得到的查询结果如下图所示:

可以看到,搜到的全部都是相似的图片,而且一个很有趣的现象是,imageNet训练的模型在这个比较特殊的图像库上竟然可以取得这么理想的结果,揣测大概是imageNet包含的图像种类很多,库中也包含了类似的样本吧,也可能是因为imageNet训练的模型足够泛化未知类别的自然图像。后面还用其他的图像做了些测试,效果都比较好。当然,毕竟用的是imageNet库,如果要在自己的库上取得更好的效果,还是需要自己训练才行,不过退一步来讲,至少从方法上来讲,这个是完全可行的,而且在精度方面可以进一步优化,前期把框架搭建起来形成可用的系统才是最重要的。
另外,原本想的是,因为要满足两种需求,而目前还没有哪种比较好的方法能满足这样一种需求,所以设想的是在界面上设置两个按钮,后台运行两种方法,一个按钮负责相同物体的搜索,一个按钮负责相似物体的搜索。后来再经过仔细思考后,发觉这个方案可以进一步优化,比如先搜索相似,然后在相似的里面在相同,前面搜索相似相当于一个过滤或者说是分类的过程,这样就使得得到的图片都是相似的,而返回的结果里前面都是相同的。
参考:




