
CVPR 2011《Iterative Quantization: A Procrustean Approach to Learning Binary Codes》论文阅读笔记。看过的文章,不做记录,即便当时理解透了,过一段时间后,知识总会模糊不清。所以从现在开始,对一些自己阅读过的一些精彩的文章,悉心记录,方便自己查阅温故,当然如果对同行有所裨益的话,亦是一件开心的事。 好了,回归正题。这篇文章发表在2011年CVRP上,一作是Yunchao Gong,师从Sanjiv Kumar,关于Sanjiv Kumar可以到她的HomePage上了解。
这篇文章的主要思路是先对原始空间的数据集\( X \in R^{n\times d} \)用PCA进行降维处理,设经过PCA降维后的数据集为\( V \in R^{n\times c} \),该问题就可以转化为将该数据集中的数据点映射到一个二进制超立方体的顶点上,使得对应的量化误差最小,从而而已得到对应该数据集优良的二进制编码。
对于PCA降维部分,不做详解,具体可以参阅该文。设\( v\in R^c \)为原特征空间中某一数据点经过PCA降维后的表示形式,对应在超立方体中的顶点用\(sgn(v)\in \{ -1,1 \}^c \)来表示,要使量化误差最小,即\(v\in R^{c}\)与\(sgn(v)\in \{ -1,1 \}^c\)的欧式距离最小,即\( \min||sgn(v)-v)||^2\ \),对于所有的数据点进行二进制编码后用B表示,PCA降维后\(V=X \times W\),对整个数据集为\(\min||B-V||^2\)。由于对矩阵进行旋转可以降低量化误差,如下图示:
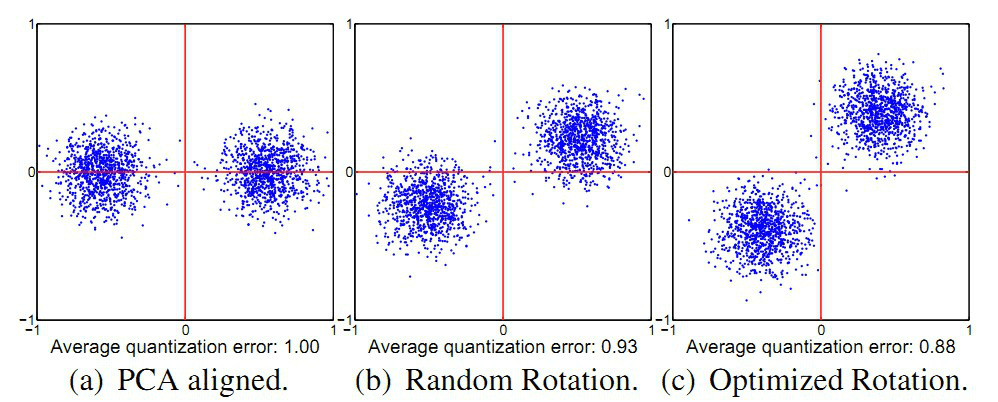
从图1可以看出,对投影后的矩阵V进行随机旋转后,量化误差降低至0.93,对于找到的最优的旋转矩阵,量化误差降低至0.88(矩阵与正交矩阵相乘实际上就是对矩阵做旋转)。基于这样一个事实,考虑将投影后的数据集V进行旋转变换,\(min||B-V||^2\)便变换为\(]min||B-VR||^2\),R为旋转矩阵。整个问题域就变成了\(min||B-VR||^2\)的优化问题,即找出最优的旋转矩阵R和与之对应的编码B。该式的优化可以采用交替跌倒的求解方法:先生成随机矩阵并对其进行SVD分解得到对应的正交矩阵作为R的初始值,然后固定R求B,\(B=sgn(V \times D)\)(注意这里截距\(b=0\),因为在原空间已对数据中心化,非常重要),B求出来再通过对\(B \times V\)进行SVD更新R,交替迭代若干次即可,文中选用的是50次。
通过上面过程便可经过PCA降维后的数据完成编码过程,后面的相似性采用汉明距离进行度量,这里不赘述。
总结一下,整个过程可以概括为:先对数据集进行PCA降维,然后寻找量化误差最小的旋转矩阵即可得到对应该最优旋转矩阵下的特征向量的二进制编码。
论文给出了检索飞机的一个实例效果:

Yunchao Gong Homepage上公开了Matlab源码,不过并不提供数据库,直接运行不了,小白菜已经对源码进行了modify,有需要的可以看LSH、ITQ、SKLSH图像检索实验实现(Code)这篇文章,在这篇文章中提供了modified后的代码,也可以直接到小白菜的GitHub主页上下载hashing-baseline-for-image-retrieval,其中有ITQ的代码。
[1] Yunchao Gong and S. Lazebnik. Iterative Quantization: A Procrustean Approach to Learning Binary Codes. In: IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), 2011.




