
本文翻译自:Pedestrian Detection OpenCV。
你知道OpenCV里面已经内置的行人检测方法吗?在OpenCV里面,有一个预先训练好了的HOG+线性SVM模型,能够对图像和视频中的行人进行检测。如果你还不熟悉方向梯度直方图HOG和线性SVM方法,我建议你阅读方向梯度直方图和物体检测这篇文章,在这篇文章中,我对该框架分了6步进行讨论。
如果你已经熟悉了这个过程,或者你仅仅只是想看看OpenCV行人检测的代码,那么现在就打开一个新文件,并将它命名为detect.py,开始我们的编程之旅吧:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# import the necessary packages
from __future__ import print_function
from imutils.object_detection import non_max_suppression
from imutils import paths
import numpy as np
import argparse
import imutils
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--images", required=True, help="path to images directory")
args = vars(ap.parse_args())
# initialize the HOG descriptor/person detector
hog = cv2.HOGDescriptor()
hog.setSVMDetector(cv2.HOGDescriptor_getDefaultPeopleDetector())
第2-8行导入一些我们必要的包,我们导入print_function确保我们的代码同时在Python2.7和Python3上兼容,这样可以使得我们的代码能够在OpenCV2.4.X和OPenCV3上都能够工作,然后,从我的imutils包中我们导入non_max_suppression函数。
如果你还没有安装imutils,可以通过pip来安装:
$ pip install imutils
如果你已经安装了imutils,你需要把它更新到最新版(v0.3.1),在这个版本里面,包含了non_max_suppression函数的实现,以及其它一些微小的更新:
$ pip install --upgrade imutils
我已经在我的PyImageSearch博客上在两次讲到过非极大抑制(non-maxima suppression)方法,一次是在Python非极大抑制用于物体检测,一篇是在用Python实现更快的非极大抑制,无论是哪一种情形,非极大抑制的宗旨都是获取多个重叠的边框(bounding box),并且将他们减少至仅有一个边框。

非极大抑制方法可以减少在进行行人检测过程中的假阳率。
第11-13行处理我们命令行传入的参数,这里,我们只需要一个切换--images,用它来传入待检测行人的图像目录。
最后,第16行和17行初始化我们的行人检测器。首先,我们调用hog = cv2.HOGDescriptor()来初始化方向梯度直方图描述子,然后,我们调用setSVMDetector来设置支持向量机(Support Vector Machine)使得它成为一个预先训练好了的行人检测器。
到了这里,我们的OpenCV行人检测器已经完全载入了,我们只需要把它应用到一些图像上:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
# import the necessary packages
from __future__ import print_function
from imutils.object_detection import non_max_suppression
from imutils import paths
import numpy as np
import argparse
import imutils
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--images", required=True, help="path to images directory")
args = vars(ap.parse_args())
# initialize the HOG descriptor/person detector
hog = cv2.HOGDescriptor()
hog.setSVMDetector(cv2.HOGDescriptor_getDefaultPeopleDetector())
# loop over the image paths
for imagePath in paths.list_images(args["images"]):
# load the image and resize it to (1) reduce detection time
# and (2) improve detection accuracy
image = cv2.imread(imagePath)
image = imutils.resize(image, width=min(400, image.shape[1]))
orig = image.copy()
# detect people in the image
(rects, weights) = hog.detectMultiScale(image, winStride=(4, 4),
padding=(8, 8), scale=1.05)
# draw the original bounding boxes
for (x, y, w, h) in rects:
cv2.rectangle(orig, (x, y), (x + w, y + h), (0, 0, 255), 2)
# apply non-maxima suppression to the bounding boxes using a
# fairly large overlap threshold to try to maintain overlapping
# boxes that are still people
rects = np.array([[x, y, x + w, y + h] for (x, y, w, h) in rects])
pick = non_max_suppression(rects, probs=None, overlapThresh=0.65)
# draw the final bounding boxes
for (xA, yA, xB, yB) in pick:
cv2.rectangle(image, (xA, yA), (xB, yB), (0, 255, 0), 2)
# show some information on the number of bounding boxes
filename = imagePath[imagePath.rfind("/") + 1:]
print("[INFO] {}: {} original boxes, {} after suppression".format(
filename, len(rects), len(pick)))
# show the output images
cv2.imshow("Before NMS", orig)
cv2.imshow("After NMS", image)
cv2.waitKey(0)
在第20行我们对我们的--images目录下的图像进行循环,这篇博文中使用的例子样本是从INRIA Person Dataset这个很流行的人物库上抽取的,更具体的说,是从GRAZ-01子集中抽取出来的,这些图片存放在源码目录下面了。
第23-25行载入磁盘中的图像,并且将图像裁剪到最大宽度为400个像素,之所以降低我们的图像维度(其实就是之所以对我们的图像尺寸进行裁剪)主要有两个原因:
真正对图像中的行人进行检测的代码是在第28行和29行,通过调用detectMultiScale的hog描述子方法。这个detectMultiScale方法构造了一个尺度scale=1.05的图像金字塔,以及一个分别在x方向和y方向步长为(4,4)像素大小的滑窗。
窗口的大小固定在32*128像素大小,这个设置是按照 seminal Dalal和Triggs论文来设置的。detectMultiScale函数会返回一个2-元组的rects,或者是图像中每一个行人的边框坐标(x,y),以及由SVM在每一次检测中返回的weights置信值(我们一般也成为分数,译者注)。
scale的尺度设置得越大,在图像金字塔中层的数目就越少,相应的检测速度就越快,但是尺度太大会导致行人出现漏检;同样的,如果scale设置得太小,将会急剧的增加图像金字塔的层数,这样不仅耗费计算资源,而且还会急剧地增加检测过程中出现的假阳数目(也就是不是行人的被检测成行人)。这表明,scale是在行人检测过程中它是一个重要的参数,需要对scale进行调参。我会在后面的文章中对detectMultiScale中的每个参数做些调研。
第32行和33行获取我们的初始边框,并将它们在图像上框出来。
不过,你将会看到在一些图像上有的行人框出来的框,有很多重叠的边框,如上面1图所示。
针对这种情况,我们有两种选择。一种选择是检测一个边框是否完全包含了另一个边框(你可以看看OpenV中的一些实现例子)。另外一种选择是应用非极大抑制方法,通过设置一个阈值来抑制那些重叠的边框,这就是第38行和39行所干的事。
注意:如果你想了解更多HOG框架和非极大抑制,我推荐你阅读方向梯度直方图和物体检测。在那篇博文中,你可以查看Python非极大抑制用于物体检测,以及后面更新的Malisiewicz方法。
在应用非极大抑制后,我们在第42行和43行画出最终的边框,在第46-48行中我们展示图像的一些基本信息,以及检测到的边框数目,在第51-53行,在屏幕最终显示我们输入的图像。
行人检测结果
为了看看我们写的行人检测脚本的实际效果,我们只需要执行下面命令:
$ python detect.py --images images
下图是一张行人检测的结果图:

上图我们检测到了站在警车旁的单个行人。

上面我们可以看到在前景中的男人被检测到了,同时背景中推着婴儿车的女人也检测到了。
图4的例子展示了为什么用非极大抑制很重要。detectMultiScale函数除了将正确的边框检测出来外,还把两个边框边框检测出来了,这两个错误的边框将图像中的行人覆盖了。通过使用非极大抑制,我们可以抑制错误的边框,只留下正确检测的边框。

我们再一次可以看到,有很多错误的边框被检测出来了,通过使用非极大抑制,我们可以抑制错误的边框,只留下正确检测的边框。

图6在一个购物中心进行行人检测,图中,有两个人正向摄像头走进,另外一个人正远离摄像头,不管是哪种情形,我们的HOG检测方法都能够准确的检测出行人。在non_maxima_suppression 函数中较大的overlapThresh能够确保那些部分重叠了的边框不会被抑制。

老实说,我对上面图片的检测结果有点儿惊讶,因为一般而言HOG描述子在运动模糊的图片上检测效果不是很好,不过在这幅图像上,我们却将行人检测出来了。

这里有另外一个多个重叠边框的例子,不过因为我们的overlapThresh设置得比较大,所以这些边框没有被抑制,从而能够将正确的检测结果留下来。

图9的例子展示了HOG+SVM行人检测器的多功能性,我们不仅能够检测到成年的男人,也能够检测到那三个小孩(注意:该检测器不能检测到躲藏在他老爸后面的小孩)。
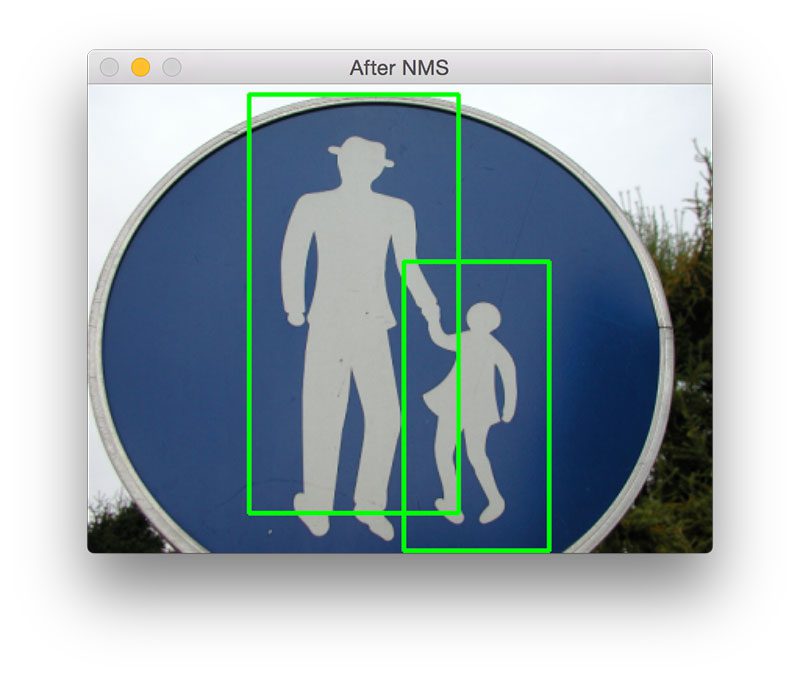
我将图10放在最后是因为我发觉这非常的有趣,我们可以很清楚的看到这只是一个路标标识,标识表示人行横道,然而,HOG+SVM检测器将它们在图中框出来了,实际上它们却并不是行人。
总结
在这篇博文中,我们已经学到了怎样使用OpenCV的库以及Python来进行行人检测。
实际上OpenCV库已经内置了一个预先训练好了的HOG+线性SVM检测器的模型,它是基于Dalal和Triggs论文里的方法来自动的实现图像中行人的检测。
虽然HOG的方法比Haar counter-part的精度要高,不过它仍需要对detectMultiScale进行合理的设置。在后面的博文中,我会对detectMultiScale中的每一个参数做一个调研,已经怎样调参的细节,并陈述在精度和性能之间的折中。
不管怎么说,我都希望你喜欢这篇博文!我正打算在后面给出更多的关于物体检测的教程,如果你希望这些教程出来后能够获得及时的通知,你可以考虑订阅我的博客。
我已经在PyImageSearch Gurus course里面包含了HOG+线性SVM的物体检测方法,你可以看看。




