
MHA、MQA、GQA差异
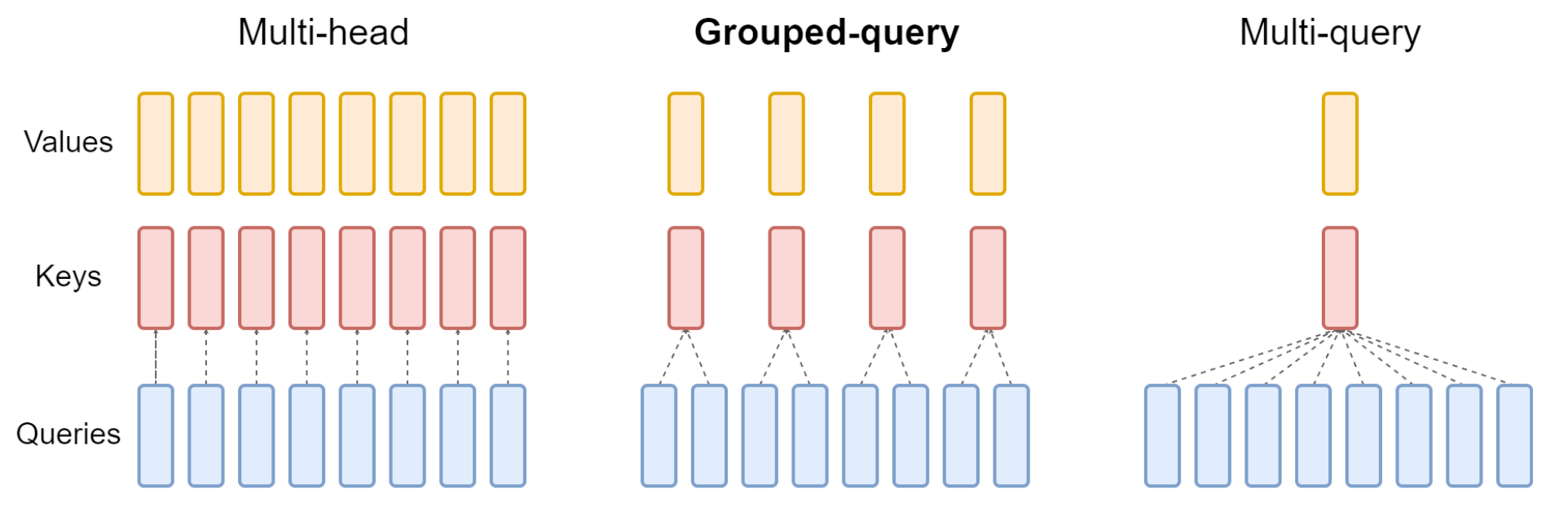
MHA:Multi-Head Attention,QKV 三部分有相同数量的头,且一一对应。每次做 Attention,head_i 的 QKV 做好自己的运算就可以,输出时各个头加起来就行。
MQA:Multi-Query Attention,让 Q 仍然保持原来的头数,但 K 和 V 只有一个头,相当于所有的 Q 头共享一组 K 和 V 头,所以叫做 Multi-Query 了。
- 实现改变了会不会影响效果呢?确实会影响,但相对它能带来的收益,性能微降是可以接受的。能带来多大的收益呢?实验发现一般能提高 30%-40%左右的吞吐。收益主要来源于降低了 KV cache。实际上 MQA 运算量和 MHA 是差不多的,可理解为读取一组 KV 头之后,给所有 Q 头用,但因为之前提到的内存和计算的不对称,所以是有利的。
GQA:Grouped-Query Attention,是 MHA 和 MQA 的折衷方案,既不想损失性能太多,又想获得 MQA 带来的推理加速好处。具体思想:不是所有 Q 头共享一组 KV,而是进行分组,一定头数 Q 共享一组 KV,比如上面图片就是两组 Q 共享一组 KV。
MHA、MQA、GQA共性
实际上,MHA、MQA可以看做是GQA两个特例版本:
- MQA对应GQA-1,即只有一个分组,对应一个K和V;
- MHA对应GQA-H,对应H个head,对应H个K和V;
从MHA模型得到MQA和GQA
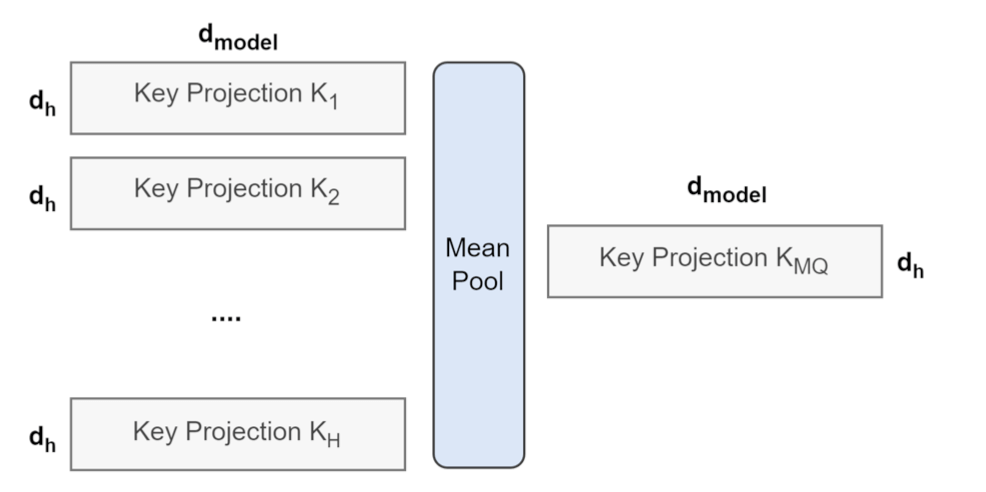
- 从MHA得到MQA:将MHA中H个head的的K和V,分别做mean pooling后得到一个K和V,用得到的K和V继续训练;
- 从MHA得到GQA:将MHA中H个head的的K和V,分别做mean pooling得到H个K和V,用得到的K和V继续训练;
MHA、MQA、GQA效果
在LLAMA2中,在不同的数据数据集上对比的效果(注意:为了维持参数量一致,对于MQA、GQA的FFN layer的维度,会有一定的拓宽):





