SIGIR 2022 Clustering based Behavior Sampling with Long Sequential Data for CTR Prediction paper reading分享时记录的笔记。
背景
对当前target item预估时,序列建模要解决的两个主要问题:
- 用户行为序列中存在很多噪声:First, there is a lot of noise in such long histories, which can seriously hurt the prediction performance.
- 行为序列太大会导致推理耗时与存储消耗比较大:Second, feeding the long behavior sequence directly results in infeasible inference time and storage cost.
User Behavior Clustering Sampling (UBCS)解决上述两个问题的思路:
- 建模一种同时考虑相关性(行为序列与target item的相关性)、又考虑时间信息的行为序列采样模块(Behavior Sampling module);
- 将行为序列item进行小数量级别的聚类,即Item Clustering module;
对于行为序列中,包含噪声,怎么处理,总体的原则是:对于每一个target CTR prediction,从用户行为序列中,挑选出那些与target CTR prediction最相关的那些样本出来。
整体框图
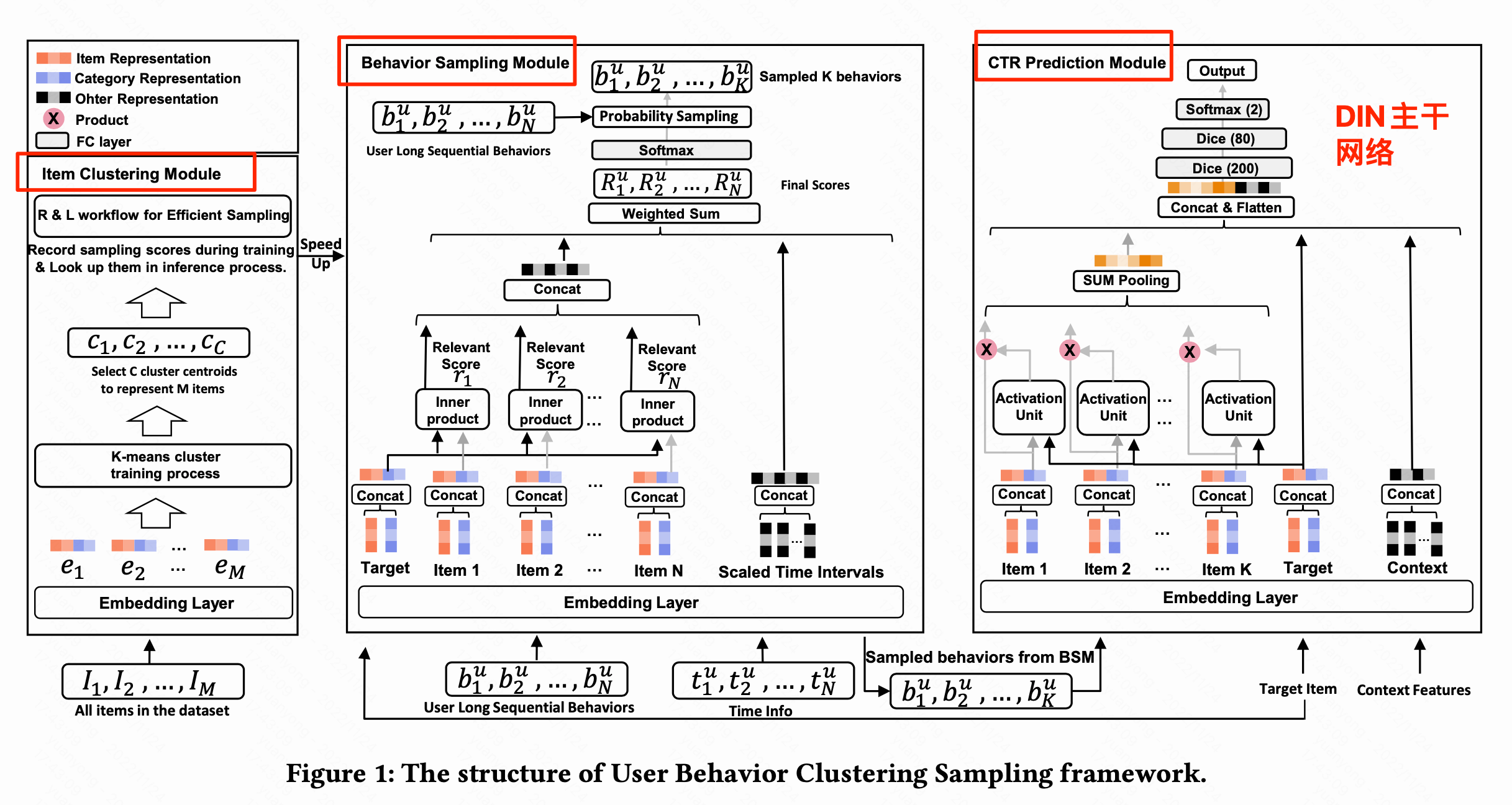
Behavior Sampling Module
用户的长行为序列,不仅包含了用户丰富的兴趣信息,也包含了很多不相关行为和噪声。所以需要做相关性提取。
相关性提取
用户行为长序列中的每个item和candidate item分别计算相关性分:
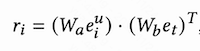
其中,e_i是行为序列embedding,e_t是target item embedding。
时间感知采样

计算行为序列中的item和target item之间的时间差,embedding后,和相关性相加,在通过softmax选取top K, 就是采样出来的K个item序列。

对于长序列用户行为建模,输入的用户行为特征序列过长,使得原有的监督学习标签变得相对稀疏,模型难以获得足够的训练信号。
CTR Prediction Module
ctr预估,二分类,交叉熵,直接看公式,没啥可解释的:
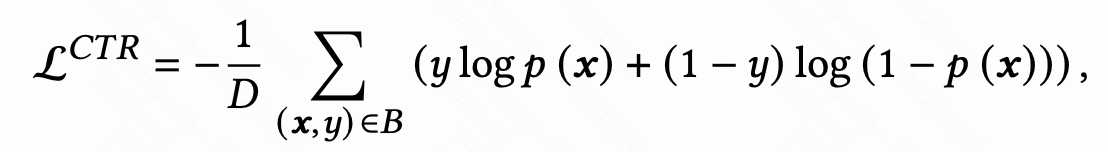
在这个模块,在训练的时候,通过构造自监督信号来进行对比学习,进行模型的预训练。为啥要进行训练?
作者的解释:长序列用户行为建模,输入的用户行为特征序列过长,使得原有的监督学习label变得相对稀疏,从而使模型难以获得足够的训练信号。

构造的自监督信号:锁定user_id、target item,label则也固定了,在采用的时候,采样出两个子序列p和q。p的正负样本,分别为:
- 正样本为q;
- 负样本为q帽子,q帽子是从一个batch里面随机负采样来源不同user的item构成的子序列;

用对比学习先进行预训练。
Item Clustering Module
item clustering module要解决的问题:由于用户行为序列很长,U个用户,M个target,计算下面内积的复杂度O(UMT)。有没有办法把M压下去,让C « M?
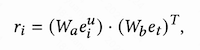
item clustering module,给出的方式是,可以借助聚类的方式,先聚类,然后计算每个用户的行为序列中的item与聚类中心的距离,在训练的时候,查表即可实现加速。整个加速过程,跟PQ极为相似。
- 在每一轮训练之前,先用target item的embedding,训练聚类C;
- 计算用户行为序列与C之间的距离;
- 开始训练,查表;
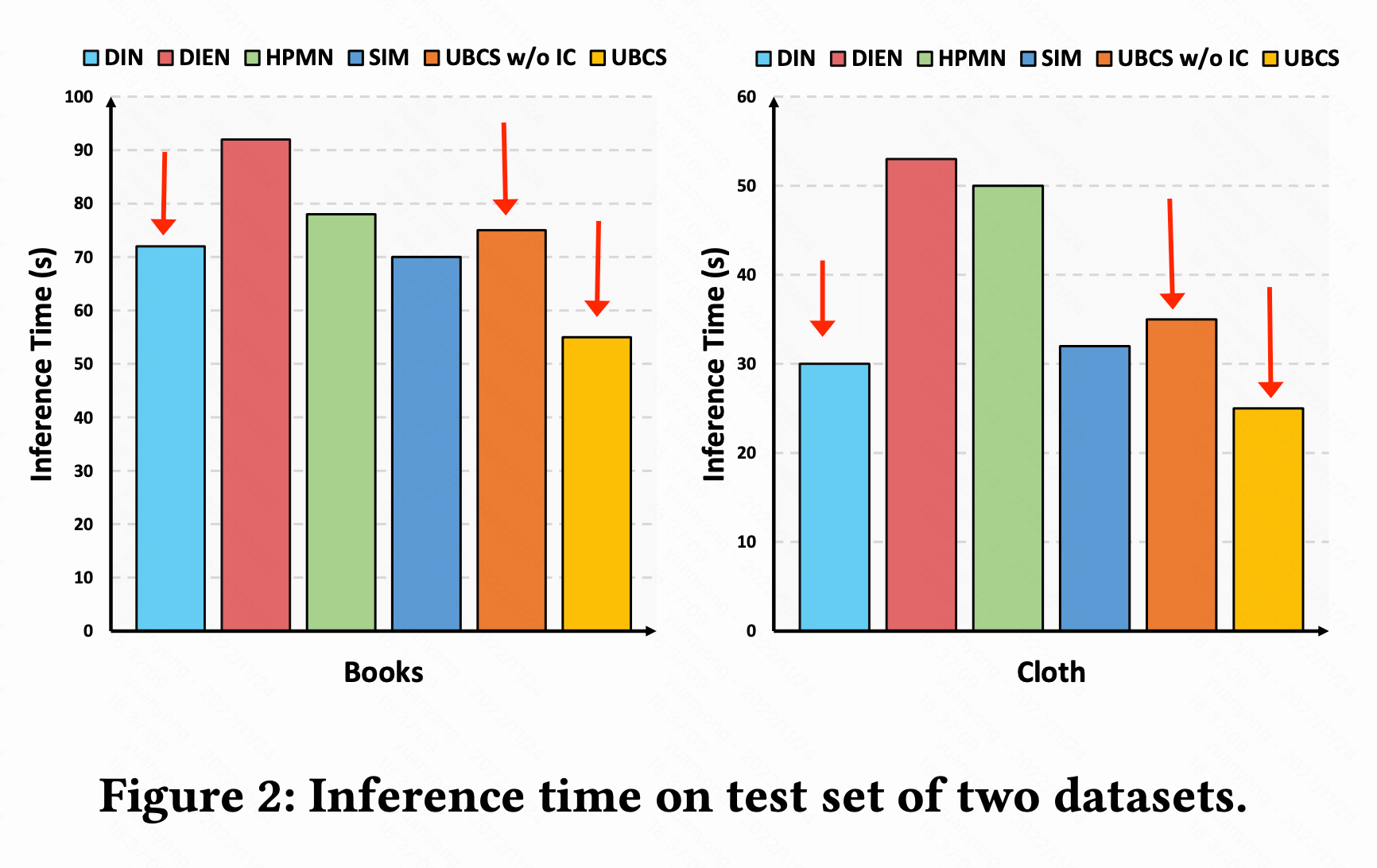
实验
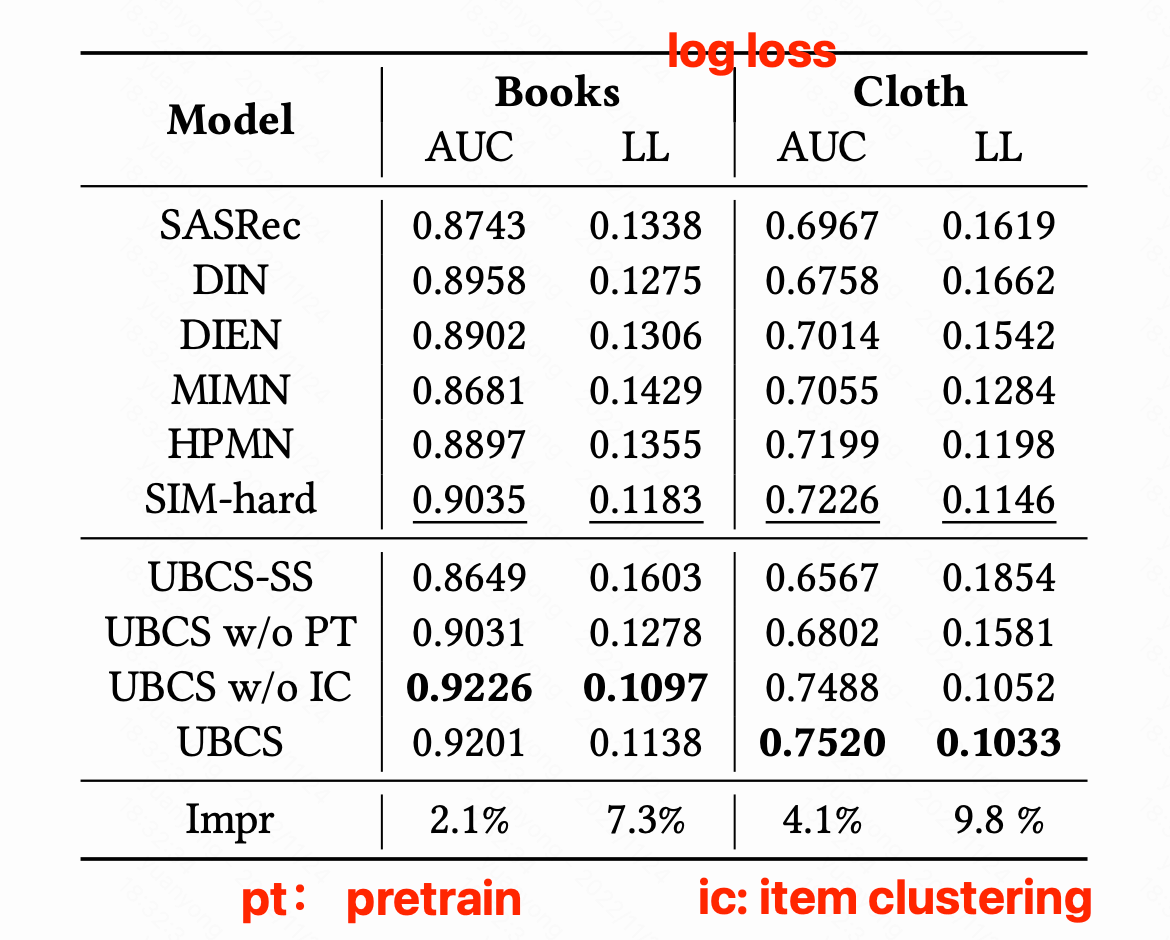
- SIM: sim hard
- MIMN: Multi-channel user Interest Memory Network
- HPMN: Hierarchical Periodic Memory Network