
背景
本篇博文,讨论的是基于内容的视频检索,即以视频搜视频。常见的应用,主要包括:
- 视频内容查重、内容打散、版权保护;
- 内容审核,分类、检测搞不定的,建灰产黑产库;
- 影视ip内容识别召回源;
技术做得世界顶尖的公司,比如Videntifier。关于Videntifier,是大白菜很佩服的一家公司,后面有时间再表。
问题
每一个视频抽取n帧,n是变化的,有的视频长抽的帧数多,有的视频短抽的帧数相应的也少一些。在索引的时候,将所有视频的帧都索引在一起。对于查询的视频,同样抽取视频帧,假设抽取到了m帧,那么问题来了,对这m帧的查询结果,其排序逻辑该如何设计?
多帧相似性度量
对于文章开头提出的问题,可以先对其进行简化,先思考这样一个问题:两个视频,如何度量两个视频的相似性(引申问题:如果校验两个图片或两个视频是重复的)?
如果两个视频,其提取的特征是视频维度的全局特征,即每个视频最终表示成了一个全局向量表示(比如iDT、C3D等特征),那么度量两个视频间的相似性时,可以直接计算它们之间的余弦相似性或者欧式距离等。这样固然最省事,但在实际应用中,当视频存量上亿,并且还有源源不断的视频添加进来时,显然基于视频维度提特征的方式因为耗费资源太大而无法得以在具备实时性要求的场景中加以应用。因而实际中在对视频内容做相关理解与分析的时候,往往是基于抽帧的方式(如何抽帧以及是否做关键帧检测在此不表)。在获取到视频的帧后,可以在此基础上提取视频维度的特征,或者提取帧级别的特征。
小白菜简单地总结视频维度特征与帧级别特征(类似全局特征和局部特征)的优劣:
- 视频维度特征:考虑了时空维度信息,有利于表述整个视频发生的事件等全局信息,表达的特征更紧凑;
- 帧级别特征:最大的缺陷在于未考虑视频时间维的信息,将帧与帧之间孤立起来了。当然帧级别的特征,其对视频空间信息的特征描述的力度更细一些,在某些场景中,比如校验两个视频是否是重复视频,基于帧级别的特征反而更适用;
一般而言,抽取视频维度的特征通常是非常耗时的。因而,实际面向视频的应用,除非场景应用非常有价值且规模不大可能会使用视频维度的特征,大部分的视频内容理解往往是基于帧级别的特征。现在回到本节开头的问题:两个视频,如何度量两个视频的相似性?这个问题小白菜曾在机器视觉:Asymmetry Problem in Computer Vision中介绍累积最小(最大)距离非对称问题时有涉及过,可以看出,累积最小(最大)距离极其符合该应用场景。因而,对于两个视频,要度量两个视频的相似性,可以采用累积最小(最大)距离,即:
\begin{equation} S(X, Y) = \sum_{i=1}^{i=n} \sum_{j=1}^{j=m} d_\min(x_i, y_j) \end{equation}
累积最小(最大)距离在应用的时候,可能会出现A视频中的多个帧匹配到B视频中的一帧或交叉匹配的情况(视频序列是时序的)。对于这种情况,在算帧匹配的时候,可以使用动态规划(DP)方法避免出现多帧和一帧匹配或交叉匹配,并确保得到的$S(X,Y)$又是最小的。当然,直接计算累积最小(最大)距离也依然是很好的。实际应用中,这种基于累积最小(最大)距离的多帧相似度度量经受住了应用的考验,而且计算效率比采用DP避免交叉匹配方式更高,并且效果很理想。
有了两个视频间多帧相似性的度量,将其拓展到一个query视频跟N个视频的相似性排序,就相比比较直观了。下面分别对暴力搜索多帧排序和OPQ多帧排序予以介绍,OPQ多帧排序是暴力搜索多帧排序的继承,只不过在对每帧查询的时候,使用的是OPQ索引,而暴力搜索则是直接query。
暴力搜索多帧排序
在不需要实时处理、对召回要求很高并且不是很频繁查询的场景,比如回溯任务中,暴力搜索仍然是一种值得推荐的搜索方法。原因有二:
- 一是特征性能发挥到最大,从而保证最好的召回率;
- 二是在特征维度不是很高的情况下(几百维,如果是CNN特征且维度较高,比如上千维,可以降到128d或者512d,损失精度通常很小),通过SSE加速,距离的计算也可以算得很快。
对于多帧排序,其排序逻辑建立在两个视频多帧相似性度量上,即对于一个query视频,库中的每个视频在与query视频做相似性度量的时候,均应采用上一节指出的累积最小(最大)距离分别计算相似度。在实际计算的时候,这种逐个视频计算的方式可以优化为query视频与N个视频进行内积运算(特征在提取的时候进行了$L2$归一化)的方式,然后对相似性矩阵做排序处理,假设query视频帧数是$m$帧,库中共$N$个视频,每一个视频取$n$帧,则相似性矩阵大小为$m \times (N*n)$,即每一行对应query视频某一帧查询后排序的结果,如下图所示:
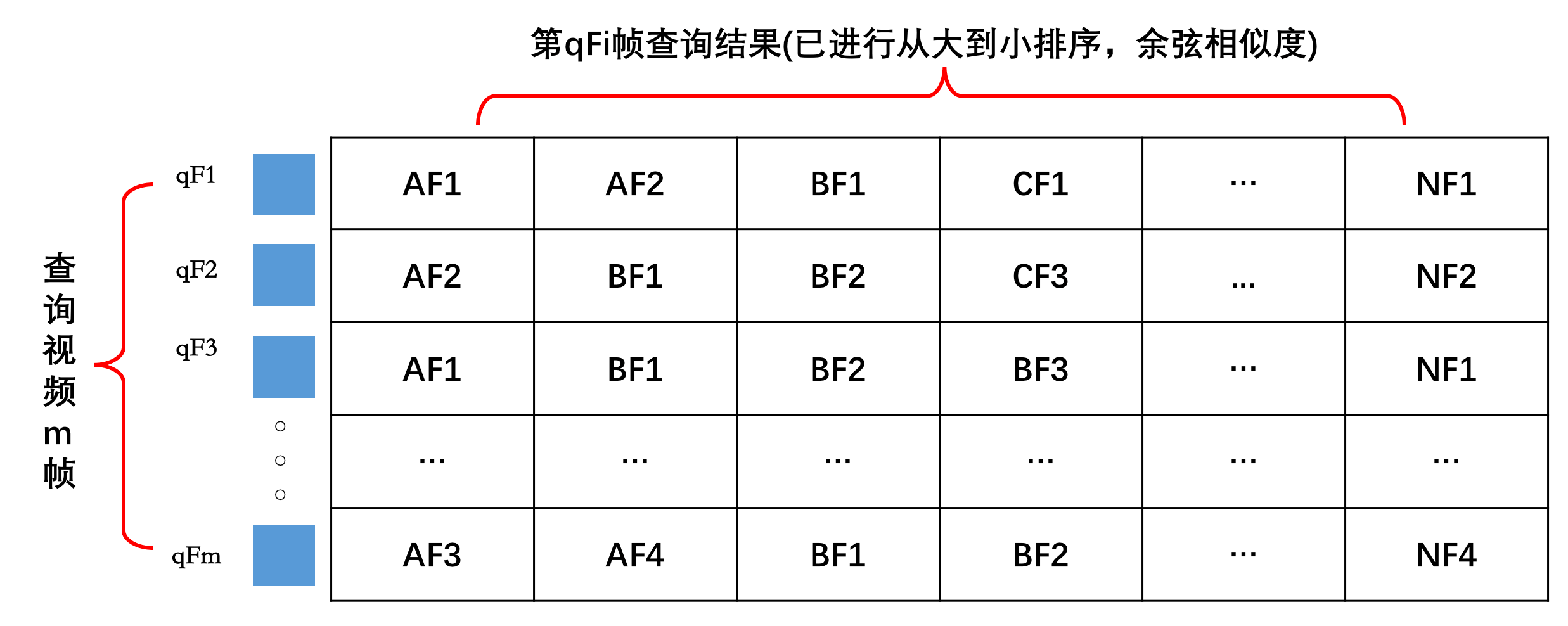
上图中,qF1表示查询视频的第1帧,AF1表示视频A的第1帧,后面以此类推。对该排完序后的相似性矩阵,我们需要对每$i(i = 0,…,m)$行取出视频id对应的最大的值(因为计算的是余弦相似度)作为该帧对应各视频id的结果,这个过程可以用下图来直观的表述出来:
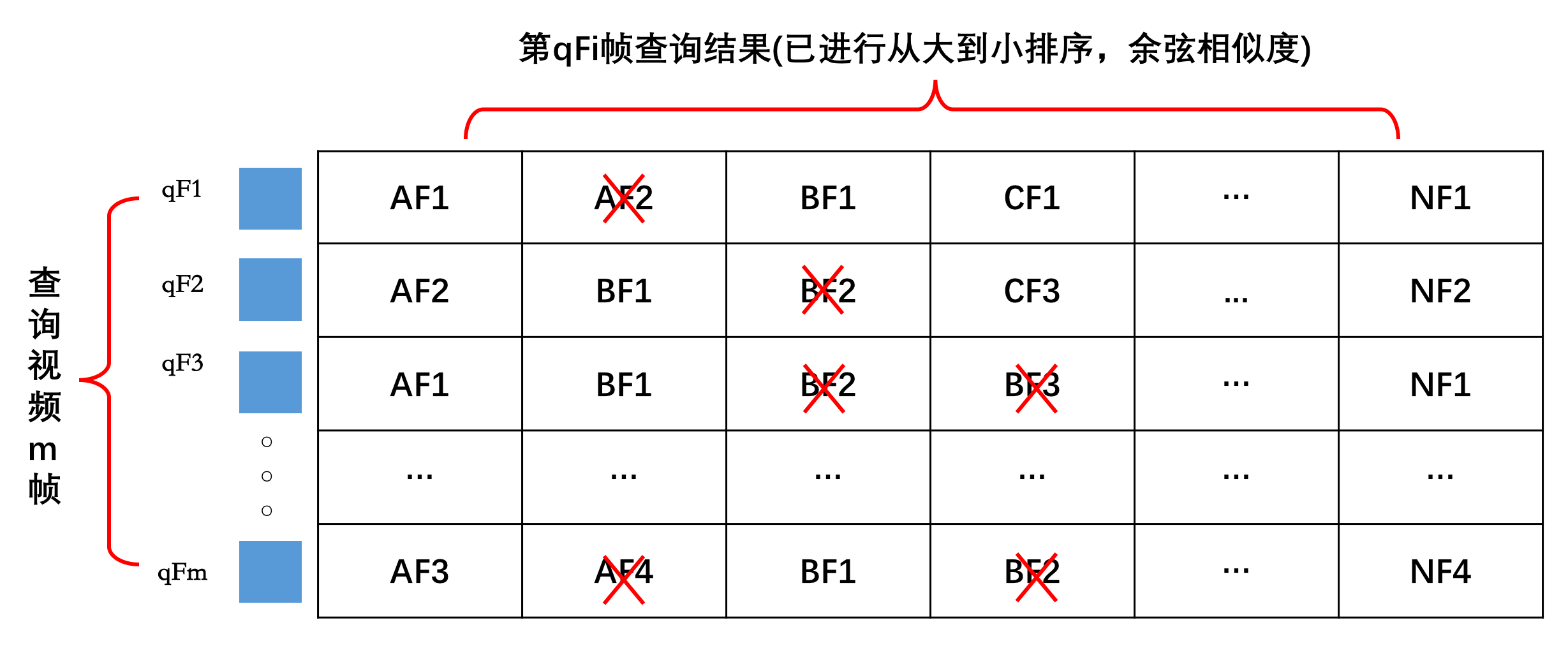
如上图所示,以qF1帧查询为例,由于已经对该帧查询的结果按相似性进行的排序,因而qF1帧查询对A视频查询的结果为AF1,其余以此类推。最后对这m帧经过最大值筛选后的结果,按视频id进行相似性分数的归并,最终得到多帧相似性排序分数,即:
A视频分数:AF1+AF2+AF1+...+AF3
B视频分数:BF1+BF1+BF1+...+BF1
C视频分数:CF1+CF3+0.0+...+0.0
上面假设C视频对于查询视频的每帧,在设置得阈值条件下无返回结果,因而用分数0.0来表示(可以视为将所有的结果在初始化的时候初始化为0)。实际query的时候,对于每一帧的查询结果,不需要将所有的查询结果返回回来,可以通过设置一个相似度阈值只返回一定数目的结果,相似度太小的返回来了也没什么用,徒增计算量和浪费资源,这样处理后排序、筛选、合并的计算量大大降低了。
OPQ多帧排序
在对实时性有要求的场景,比如上传一个视频,需要从海量的视频库中召回相同或者相似的那些视频,显然暴力搜索多帧排序无法满足要求,需要以某种近似最近邻搜索方法来构建索引。关于近似最近邻搜索方法,在此前的博文如图像检索:再叙ANN Search以及其他的博文中有过很多的介绍,这里仅以OPQ为例来介绍ANN多帧排序方法。
OPQ多帧排序方法和暴力搜索多帧排序都是基于多帧相似性度量,不同的是,由于OPQ(或PQ)计算的非对称距离,其算出来的值越小,表示两者越相似,而暴力搜索采用的是余弦相似度,其值越大表示两者越相似。因而,对于OPQ多帧排序逻辑,在设计的时候,似乎只需要为排序初始化的分数初始化一个比较合理的值,这里只对返回所有结果做初始化,下面是详细的OPQ多帧排序。
对于某查询视频queryVid,假设queryVid有m帧$(f_1,f_2,…,f_m)$,对于第i帧查询,在距离阈值小于0.1的条件下,返回了k个结果$(r_1, r_2,…,r_k)$,然后对这m帧的结果按视频id进行最小值选取与合并。举个简单的例子,假设某次查询视频只有3帧,下面是每帧查询返回的结果:
查询视频第f1帧返回的结果: A1, B1, E1, C1, D1, B2, E2
查询视频第f2帧返回的结果: B1, C2, D1, C1, E1
查询视频第f3帧返回的结果: A2, C1, B2, D2, E1, D1
对于查询视频第f1帧返回的结果,假设$A1 \leqslant B1 \leqslant E1 \leqslant C1 \leqslant D1 \leqslant B2 \leqslant E2 \leqslant 1.0 $,后面查询的同理。对上面每帧查询的结果,按视频id取最小值,得下面结果:
查询视频第f1帧返回的结果: A1, B1, E1, C1, D1
查询视频第f2帧返回的结果: B1, C2, D1, E1
查询视频第f3帧返回的结果: A2, C1, B2, D2, E1
对于第f2帧返回的结果,给A视频我们置一个比较大的阈值,比如上面提过的置为1.0来代替,表示第f2帧作为查询时,与A视频相似度差得比较大。之后,便可按视频id对结果进行合并了:
A视频分数:A1+1.0+A2
B视频分数:B1+B1+B2
C视频分数:C1+C2+C1
D视频分数:D1+D1+D2
E视频分数:E1+E1+E1
然后再对A、B、C、D、E视频上面求和后的分数从小到大排序,得到的便是最终多帧查询排序的结果。整个过程在实现的时候,可以采用partial_sort方法来完成,关于partial_sort的用法,可以参考理解你的排序操作。
无论是对于暴力搜索多帧排序、还是OPQ多帧排序,在采用了上述介绍的累积最小(最大)距离的多帧相似度度量后,跟之前采用的基于倒排查询相比,查询效果取得了极大的提升。另外对于OPQ多帧排序的结果,还可以对前top@K的结果做一次重排,能够将累积最小(最大)距离的多帧相似度度量的检索准确率发挥到最大的程度。
总结
在本篇博文中,小白菜以多帧索引及排序为主题进行了一些讨论,包括了
- 多帧相似性度量
- 暴力搜索多帧排序
- OPQ多帧排序
3个方面的内容,这些内容在视频搜索上一般都会涉及。关于多帧索引及排序的问题,学术上能够查询的论文比较少,这里小白菜结合自己的理解以及应用实践总结了小部分的经验,希望对遇到这方面问题的小伙伴有些参考的价值,也欢迎在一线从事CBIR的小伙伴拍砖交流。




