
在视频多帧排序里,大白菜有提到过Videntifier这家做图像、视频检索的公司,在这篇博文里,详细介绍下这家公司以及该公司的主要检索技术。
Videntifier概况
Videntifier科技公司是一家冰岛的软件公司(员工大概17个),成立于2007年9月,该公司起源于雷克雅未克大学的数据库实验室,Herwig Lejsek从2007年到2019年任CEO(卸任后任董事会成员),在博士期间就从事这方面的研究。Videntifier主要构建于两项专利技术——视觉指纹技术和数据库技术:
- 视觉指纹技术:对图片、视频文件在解码的时候,提取局部特征,得到一组由72个数字组成的序列(每个指纹最终由6字节表示)。对于视频,会经过scene等方式过滤掉重复、相似的局部特征,从而在视频上,能极大的降低局部特征的数量;
- 数据库技术:NV-tree数据库(受专利保护),是一种非常高效近似最近邻查找技术,其查找时间复杂度与数据量大小无关,可以近似认为是常数复杂度,并且是一种针对磁盘数据结构设计的高维向量索引技术;
Videntifier目前服务的客户包括facebook、instagram、interpol等,主要提供对违法视频、图片文件的自动监测、屏蔽和过滤,对视频、图片等网站提供视频版权保护。
技术分析
Videntifier几篇重要论文包括:
- NV-Tree: An Efficient Disk-Based Index for Approximate Search in Very Large High-Dimensional Collections,NV-tree详细介绍,TPAMI 2009,主要参考资料;
- Multimedia Identifier,Vid 申请的主要专利;
- Eff2 Videntifier: Identifying Pirated Videos in Real-Time,Vid用的SIFT版本,Eff2特征介绍详见4;
- Scalability of Local Image Descriptors: A Comparative Study,Eff2特征详细介绍,主要参考资料;
下面对Videntifier技术分析,主要是对上面给出的公开资料的理解整理。
特征构成等介绍
Videntifier使用的局部特征是Eff^2(Effectiveness和Efficiency的合并缩写)特征,其基础版本来源于Nowozin实现的autopano-sift,autopano-sift相比Lowe的SIFT的特点:
- 具有更少的描述子,描述子的维度可以是36、72和128;
- 在大部分情况下,虽然autopano-sift比Lowe的SIFT数量少,但是效果要比Lowe的SIFT好;
Videntifier在使用autopano-sift的时候,使用的是72维SIFT特征。为什么是72维?原因:autopano-sift在36-72维之间的时候,生成的SIFT的质量差异比较明显,而在72-128维之间,SIFT的质量并没有很大的提升,所以最终采用了72维的描述子。同时为了限制SIFT的数量,octave并没有进行上采样。
Videntifier局部特征提取工具,实际给出的desc是80维特征,而且特征出现负数。我们知道,SIFT统计的是梯度信息,不会出现负数,这里大白菜没看明白为啥(有知道的欢迎告知😀)。videntifier提取的局部特征信息:
- 前8维:scene id, x, y, sift octave, scale, movement x?, movement y?, xx?;
- 后72维:描述子;
关键点检测优化
为了降低计算量,videntifier在Octave没有做上采样,会降低对极度缩放形变的鲁棒性,videntifier对其进行了改进:在同一个Octave内,随着scale的增加,增加更强的gamma校正(说人话:模糊得更大的图像,会加更强的gamma校正),gamma参数2 − (0.87)^n。
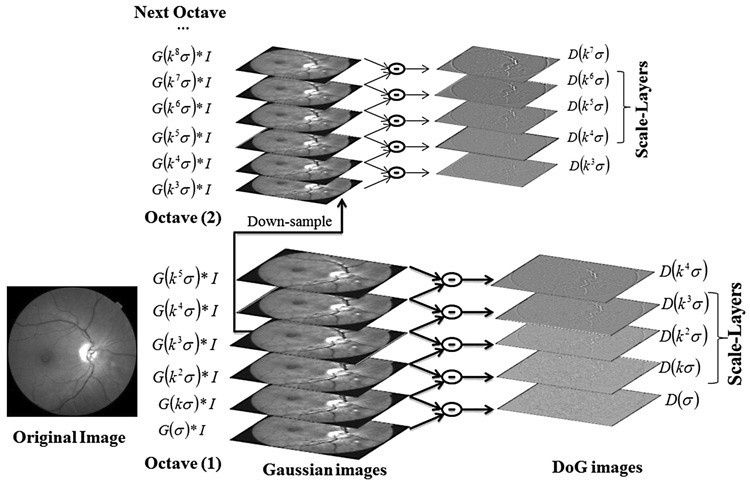
描述子优化
过滤了“line”, “bright spots” (such as spotlights and raindrops) 类型的descriptor。(这部分大白菜没太看明白,有看过的欢迎探讨)
索引建库
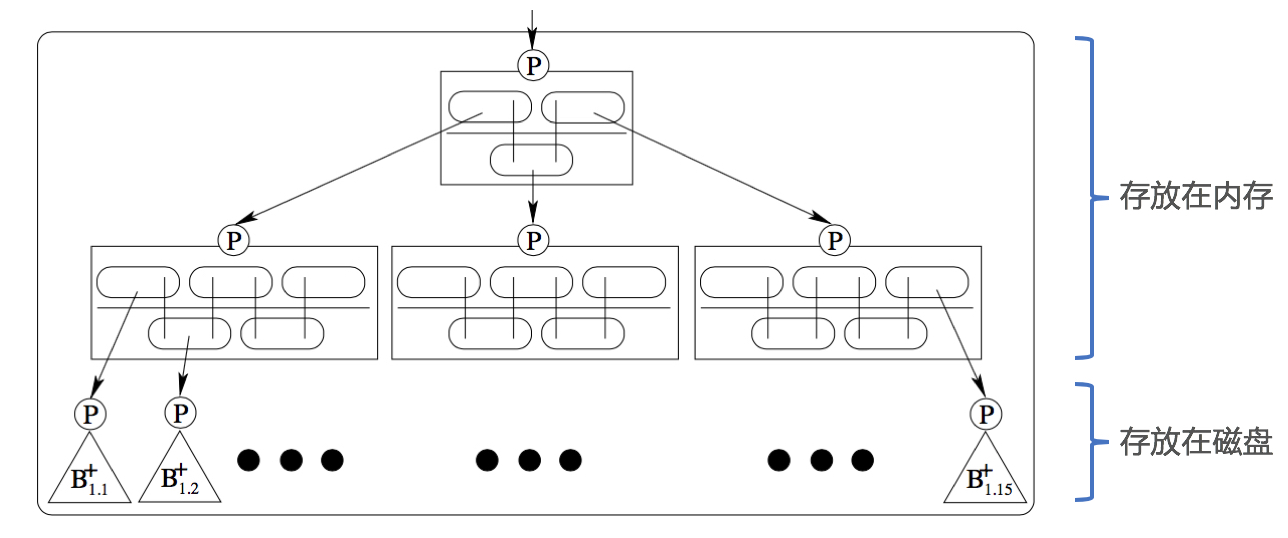
Videntifier使用的数据库索引技术是NV-tree,NV-tree的叶子节点是B+ tree,所以NV-tree具备B+ tree的所有优点:
- B+ tree的时间复杂度O(log(NH)),H是B+ tree的高度,N是样本的数目,NV-tree使用的H=1,并且会把N分割在线条的线段上,所以一次查询,可以认为接近O(H)的复杂度(查询时间跟数据的大小没什么关系);
- 磁盘I/O效率高,NV-tree的叶子节点由于是B+ tree,所以叶子节点可以存储在磁盘上,另外由于B+ tree具备”矮胖”等优点,所以磁盘I/O只需要1次或者几次即可; 所以NV-tree的查询的时候,时间与数据的大小无关;在构建索引的时候,跟数据的大小、描述子的维度有关。
NV-tree索引构建过程,主要包含两个步骤:Projecting和Segmenting,两个OP不断重复,也被成为PvS框架的原因。每一个Projecting都会将数据投影到直线上(直线可以随机生成),然后会通过Segment将直线分割成很多线段(线段与线段的分割点称为cut-points,用来指导索引创建、搜索过程),每一个线段内重复执行Projecting和Segmenting,直到线段内的描述子达到设定的数目后,不再分裂。
下图展示的是1个NV-tree和3个NV-tree的数据结构:如图所示,1个NV-tree分割策略为[3, 5],最后会得到3*5=15个分割区,每一个分割区以B+tree的方式组织描述子,并包含固定数目描述子的唯一标识符。
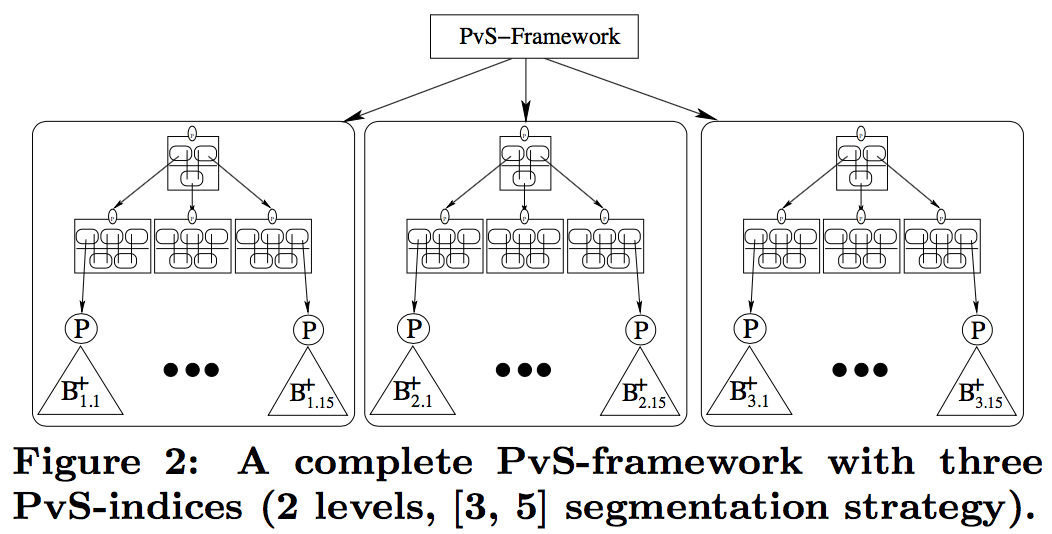
Projecting过程
Projecting的直线默认可以是随机生成的,这种方式最好是最简单并且是数据无关的。不过为了提高检索的质量,可以采用数据依赖的直线生成方式,比如PCA,在每个线段内,计算PCA,选择方差最大的特征向量作为投影的线条,当然这种方式计算量很大。所以实际在操作的时候,使用faster Approximate PCA ,即:在索引创建之前,预先生成一个大的随机线条池,放在内存中,池子中的线条满足:1)各向同性;2)两两之间准正交。
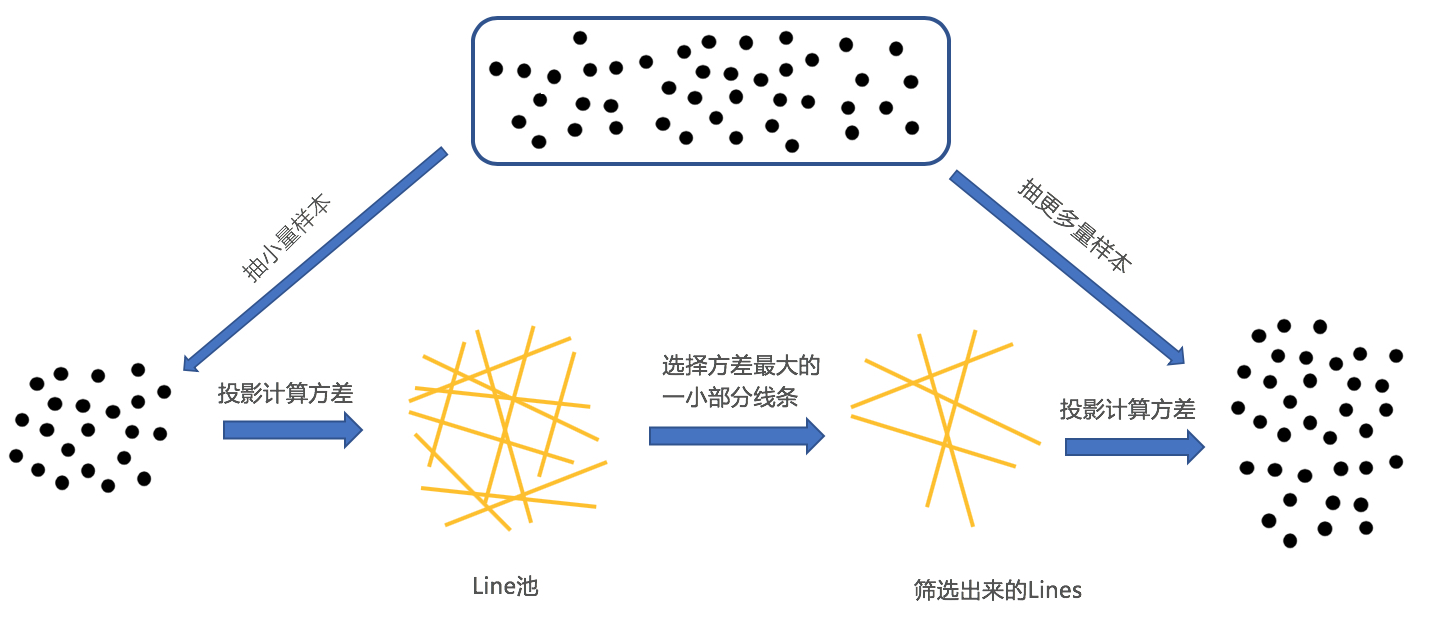
如上图所示,采样一小部分数据,投影到线条池中所有的直线上,选取一小部分具有最高方差的那些直线,然后在采样更多一点的数据,在这些具有最高方差的那些线条计算方差,从其中选择出更少的线条来,重复此过程,直到选出其中的一条来。
Segmenting过程
对于选定的投影直线(R^721),对于N个局部特征(R^172),都投影到直线上,然后对直线进行分割。分割的策略有3种:均衡分割、不均衡分割、混合方式分割:
- 均衡分割:基于基数(cardinality?相同数据量)的分割方式,这样每个线段内都具备相同的描述子数目,叶节点具有相同的大小的占用量;
- 不均衡分割:基于数据密度(正态分布)的分割方式,高密度的地方分割得更细,稀疏的地方,分割得少。这种方式会导致树更多;
- 混合方式分割:先用不均衡的方式分割,然后在每个线段内,再用均衡的方式分割内部;
索引检索过程
检索的过程与索引构建的过程类似,描述子在查询的时候,在每一个节点,通过投影到直线上,然后通过cut-points定位到是哪个子节点,进行遍历达到叶子节点。到达叶子节点后,通过一次I/O,从磁盘把叶子节点的indices读入内存,然后通过OMEDRANK排序,得到K近邻。
误匹配剔除
d(n_100, n_i) > c。
重复局部特征过滤
在视频检索时,局部特征存在高度的冗余,所以对视频类型的检索,会通过scene等方式进行过滤,剔除掉冗余特征。
测评与实验评估
在100万图片库及少量视频构成的索引库上,进行召回与准确率测试。实验评估主要从3个方面进行测量:形变、搜索的查重badcase、检索性能。
查重badcase评估情况
查重badcase包括:裁剪,静态背景干扰,画质变化,镜像,文字干扰。
对搜集的badcase准召测评:15个画中画的case,recall=100%,precision=100%。平均检索时间:
| nr_points_queried | nr_frames_queried | time_fetch_points | time_init_matching | time_matching | |
|---|---|---|---|---|---|
| 平均 | 4213 | 50 | 1492ms | 22ms | 3673ms |
公开数据集
在copydays数据集上,包括的形变有:旋转、仿射、裁剪、光照变化、画质变化、纹理较少、镜像变换,文字干扰。
对应的准召情况为:recall=89.34%,precision=95.54%,检索性能如下:
| time_fetch_points | time_init_matching | time_matching | time_query | time_total_ms |
|---|---|---|---|---|
| 17.6 | 0.745 | 97.4 | 7.28 | 304.3 |
裁剪形变自建数据集
自建了一份针对裁剪的形变数据集,里面包含了不同裁剪比例的query以及对应的原图:对应的准召情况为:recall = 89.7%, precision = 100%。
Vid优势总结
- vid的特征对多种形变的鲁棒性更好;
- vid的索引有优秀的可伸缩性,对百亿甚至千亿级别的特征,在内存消耗,时间性能和召回上依然表现很好;
- 定制化的服务,针对用户特殊的badcase,提供定制化的检测算法;




