
INS is a image retrieval system for instance search. The system can be used to retrieve same object, near-duplicate object, and copy detection, and developing the system is just for interest in my free time. I’ll improve the system contiously.
十一时期,窝在住的地方哪里也没有去,把此前闲着无事开发的INS检索系统优化了一版。优化后的效果如下:
INS概览
系统开发采用的C++和QT,在开发成桌面版本之前,复用SoTu的web界面开发了一版web系统(开发的web演示系统,将会放在flask-keras-cnn-image-retrieval中),发觉使用起来不是很方面,然后切换成桌面开发。整个开发流程相对都比较流畅,主要得益于下面两点:
- QT与C++无缝衔接。无论是语法还是信号槽等,理解起来都非常地直接,顺畅。
- OpenCV DNN模块带来的便捷。OpenCV从3.3开始,加入了DNN模块,所以不论是TensorFlow还是Caffe等主流框架训练的模型,都可以使用OpenCV做推理,不用引入一堆依赖库。
整个自由开发项目,小白菜收获了主要有3点:
- 视觉检索特征学习方式进一步深入与拓宽。这一点在后面展开。
- QT多窗口通信方式。比如主窗口打开设置参数的窗口,将参数窗口设置的信息传递给主窗口。
- 完整地打包软件。将整个项目打包,发布成一个完整的桌面安装包。
整个系统的开发,对小白菜的工程能力提升最大,因为在开发整个系统之初,整个模型差不多已经训练完了,剩下的就是把它搭成一个完整的桌面应用。下面针对视觉检索系统的特征与索引聊聊最近新收获的感悟。
INS特征学习
INS特征学习有其相对比较固定的思路,但是在不同的应用场景下,其特征学习的方式应该做相应的调整。简单的列举3个常见的场景:
- 拷贝检测场景。最常见的工业应用场景有短视频、图片拷贝检测(查重),实现流量分发控制,从而到达数字版权保护的目的。
- 实例检索场景。比如电商实例检索,比如拍立淘、Pinterst、Snapchat等主流的电商、社交平台都有自己的视觉搜索系统。
- 相似检索场景。图片推荐系统比如图片广告推荐、相似视频推荐等场景皆有应用,人脸检索里面也可以用相似人脸做一些比较有趣的创意。
相似是一个比较主观的东西,相同可以看成是相似的特例,按照这种范畴划分,在做视觉拷贝检测的时候,我们采用相似检索方式训练模型是没有多大问题的,但是将采用这种方式训练出来的模型应用到视频、图片查重中,取得的效果能不能达到最优,显然是一个大大的问号。事实上,经过我们在大规模数据集上实验验证,这种针对相似检索场景训练出来的特征,并没有针对在拷贝场景训练回来的特征更适合视频、图片查重。这里面的核心问题在于:在特征度量空间,由于重复图片形变过大,导致基于相似检索场景训练出来的模型,使得相似的图片更靠近原始图片,而形变过大的重复图片,无论我们的模型如何加约束条件,都不能将它拉得比相似的更近。
所以,如果是拷贝检测场景,应该单独训练一种能够容忍图像不同形变的特征。实际上,对于拷贝检测场景,特征与图像内容是无关的,也就是说,对于原始图像以及形变后的图像,特征不需要关注图像里面有什么样的内容,只需要关注原始图像的特征与形变后的图像特征,在度量空间里,它们是不是足够的近便可。因而对于拷贝检测这个场景,根据”特征不需要关注图像里面有什么样的内容”这个结论,我们可以得到一条非常实用的数据经验,即我们不需要对训练数据做分布上的要求。比如,为了在A平台上做拷贝检测,我们完全可以使用B平台的数据集(公开数据集),只要在训练的时候,类标签足够的大,图片的形变足够多,那么在B上训练得到的模型,直接在A上应用,也能取得非常好的效果。
下图是基于相似检索场景和基于拷贝场景训练出来的模型,在100万图库上召回率对比:
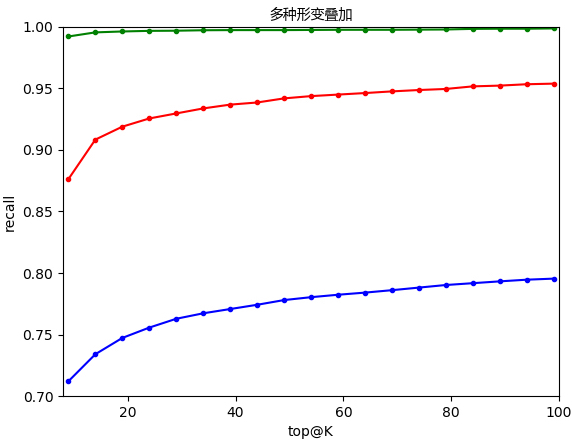
上图蓝色的曲线和红色的曲线都是基于相似检索场景训练出来的模型,绿色的线是基于拷贝检测场景训练出来的模型,可以看到,采用基于拷贝检测场景训练出来的模型,在视频拷贝检测上,召回来有了非常好的提升。同时,基于这种场景训练出来的模型,在排序上,靠前的跟偏重图片各种物理属性视觉上的相似,而不是语义上的相似。
前面我们说过,相同可以看成是相似的特例,但是上面的实验结果表明,相似检索场景与拷贝检测场景这两个东西是相悖的,分别处于事物的两个极端。要(语义)相似的话,特征形变能力会减弱;要特征抗形变能力增强,特征(语义)相似性会减弱。这两个似乎无法调和,无法统一到一起。但是,“相同可以看成是相似的特例”确实事实,所以两者虽处于事物的两个极端,但肯定是可以统一到一个框架中的。想想lambda、(1-lambda)以及多任务学习,具体怎么统一到同一个框架中,以后有机会再讲。
至于实例检索场景,通常需跟物体检测结合起来才能学习好特征,这也间接地说明,面向万物的通用实例检索系统,要做得非常的好,会碰到巨大的障碍。这也是视觉检索为什么会向垂直领域比如人脸检索、电商商品检索等发展的原因。
INS索引
INS针对的是一款桌面视觉检索软件,所以图库大小适用于中小规模(百万量级),对于中小规模应用场景,为了保证检索的高召回率,INS采用了图ANN索引算法,到具体的方法则采用了层次可导小世界索引算法(HNSW,在之前的博文OPQ索引与HNSW索引有相应介绍)。如果要拓展到百亿以上规模的量级,索引可以采用图索引跟矢量量化结合的方法,比如HNSW和OPQ一起结合起来使用。
INS后续成长点
每个做算法的同学,都踹怀着发明一种非常work、非常solid、非常先进并能成为经典算法的梦想。小白菜也希望以INS为契机,进一步不断在此领域不断深耕细作,最后成为此领域的专家。具体到INS这款自由开发的视觉检索软件,小白菜会在周末自由时间,从下面方向完善INS:
- 优化特征抽取模型,最终是把检测模块也加上;
- 索引模块优化,目前索引模块还不是很合理,索引删除未支持;
- 完善INS系统的稳健性,尽量避免出现软件崩溃;
这是小白菜开发的第一款真正可以称得上软件的系统,小白菜期待自己能够坚持下去。另外,INS暂时没有开源的计划,主要考虑到整个系统还不是很完善,效果也不是很好,等时机到了再说。




